
Introduction
Data sources ingest data in different sizes and shapes across on-premises and in the cloud, including product data, historical customer behaviour data, and user data. Enterprise could store these data in data storage services like Azure Blob store, an on-premises SQL Server, Azure SQL Database, and many more.
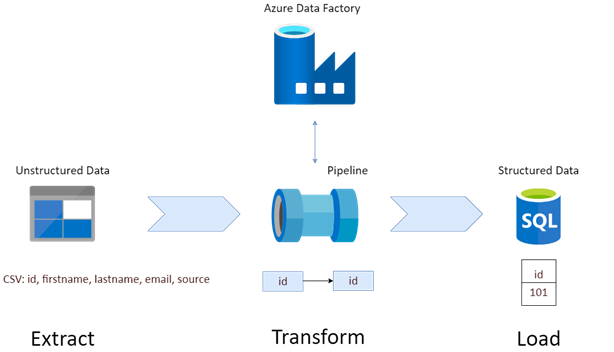
This blog will highlight how users can define pipelines to migrate the unstructured data from different data stores to structured data using the Azure ETL tool, Azure Data Factory.
What is ETL Tool?
Before diving deep into Azure Data Factory, there is a need to know what the ETL tool is all about. ETL stands for Extract, Transform and Load. The ETL Tool will extract the data from different sources, transform them into meaningful data and load them into the destination, say Data warehouses, databases, etc.
To understand the ETL tool in real-time, let us consider management with various departments like HR, CRM, Accounting, Operations, Delivery Managements, and more. Every department will have its datastore of different types. For instance, the CRM department can produce customer information; the Accounting team may keep various books, and their Applications could store transaction information in Databases. The organization needs to transform these data into meaningful and analyzable insights for better growth. Here comes the ETL tool like Azure Data Factory. Using Azure Data Factory, the user will define the data sets, create pipelines to transform the data and map them with various destinations.
What is Azure Data Factory?
As cloud adoption keeps increasing, there is a need for a reliable ETL tool in the cloud with many integrations. Unlike any other ETL tools, Azure Data Factory is a highly scalable, increased agility, and cost-effective solution that provides code-free ETL as a service. Azure Data Factory consists of various components like:
- Pipelines: A pipeline is a logical grouping of activities that performs a unit of work. A single pipeline can perform different actions like ingesting data from the Storage Blob, Query the SQL Database, and more.
- Activities: Activity in a Pipeline represents a unit of work. An Activity is an action like copying a Storage Blob data to a Storage Table or transform JSON data in a Storage Blob into SQL Table records.
- Datasets: Datasets represent data structures within the data stores, which point to the data that the activities need to use as inputs or outputs.
- Triggers: Triggers are a way to execute a pipeline run. Triggers determine when a pipeline execution should start. Currently, Data Factory supports three types of triggers:
- Schedule Trigger: A trigger that invokes a pipeline at a scheduled time.
- Tumbling window trigger: A trigger that operates on a periodic interval.
- Event-based trigger: A trigger that invokes a pipeline when there is an event.
- Integration Runtime: The Integration Runtime (IR) is the compute infrastructure used to provide data integration capabilities like Data Flow, Data Movement, Activity dispatch, and SSIS package execution. There are three types of Integration Runtimes available, they are.
- Azure
- Self-hosted
- Azure SSIS
Now let us see how to migrate the unstructured data from the Storage Blob into structured data using Azure Data Factory with a real-time scenario.
Migrate data with a real-time scenario
Consider a developer should design a system to migrate the CSV file generated from the CRM Application to the central repository, say, Azure SQL Database for automation and analytics. CSV file contains the unstructured data of more than 1000 customer records with a delimiter. These records should be efficiently migrated to the Azure SQL Database, which is a central repository. Here comes the Azure Data Factory. It allows creating a pipeline to copy the customer detail records from CSV to the CustomerDetails Table in Azure SQL Database.
Following are the steps to migrate data from CSV to Azure SQL Database:
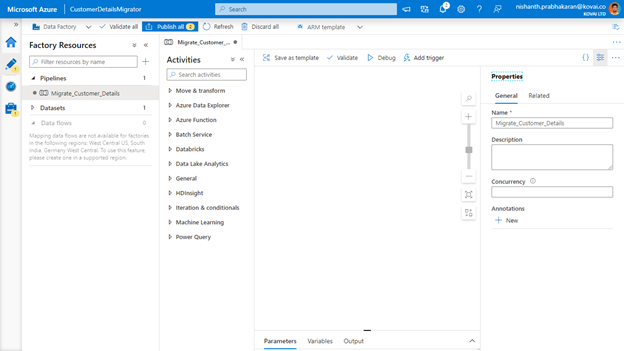
- Create an Azure Data Factory and open the Azure Data Factory Editor
- Now go to the Editor page and Click the + button to create an Azure Data Factory pipeline
- Provide the Name of the Pipeline (Migrate_Customer_Details) as shown below
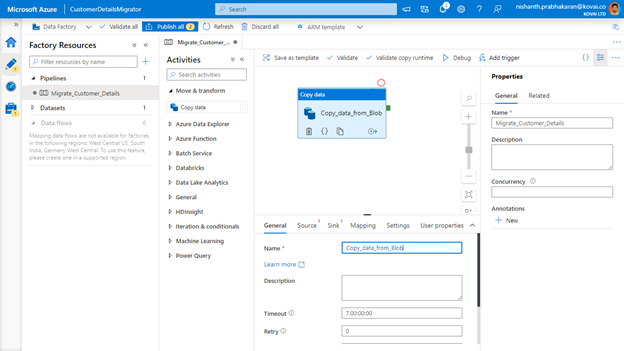
Setup Source of the Activity
- Expand Move & Transform node in the left navigation and drag Copy Data activity into the designer.
- Provide the name of the activity (Copy_data_from_Blob)
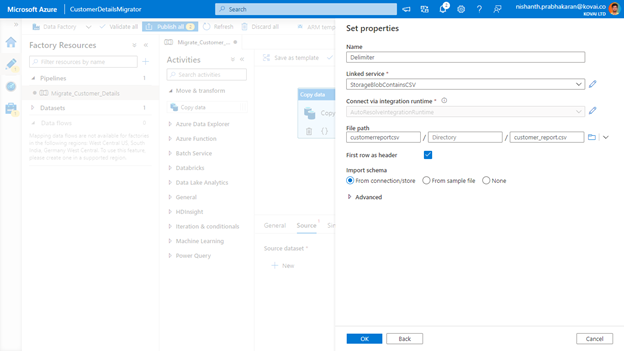
- Now select the Source tab and click +New, which will open a blade to choose a data source. Choose Azure Storage Blob as the data source and click
- In the Format Type Blade, select CSV File and click Now provide the file path and click OK to save the data source.
Setup Destination of the Activity
- Now select Sink tab and click +New, which will open a blade to choose the destination. Choose Azure SQL Database as destination and click
- Click + New in the Linked Services like and provide the Azure SQL Database connection details. Click OK to save the destination.
- Now provide the Table name and click
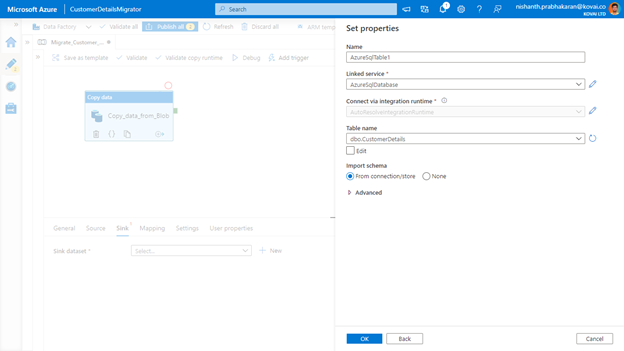
Map CSV Properties to Table Properties
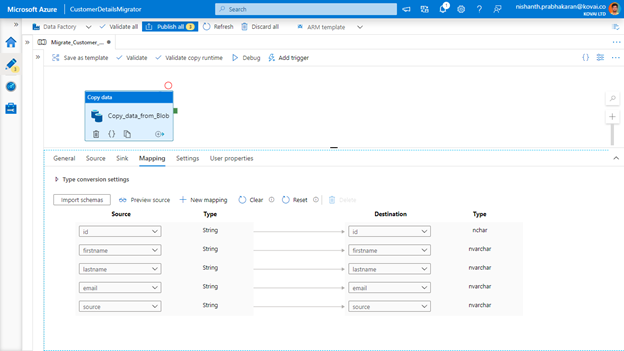
- Click the Mapping tab and press Import Schemas button to automatically detect the CSV file and map the CSV properties to Table column properties.
- If any of the mappings is wrong, it is also possible to change them manually as shown below
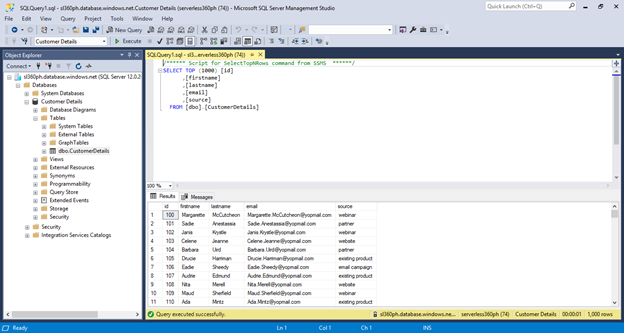
Once the mapping is done, click Debug to start the Pipeline run, which will begin to migrate the CSV data to Table. Once the Pipeline Run succeeds, check the SQL Database table to ensure the records are moved successfully.
From the above scenario, we can understand the efficiency of Azure Data Factory. Without a single line of code, the user can very easily migrate data across different datastore. Azure Data Factory offers Activities for Azure Functions, Data Bricks, Machine Learning and a lot more. User can even automate this Pipeline run using three types of triggers discussed in the above section.
Advanced Concepts:
How Turbo360 enhances the Azure Data Factory Experience?
Azure Data Factory is one of the best ETL tools in the market. It simplifies the data migration process without writing complex algorithms. Though it offers remarkable features, it also has some limitations for operation and support teams in:
- Lack of Application-level grouping
- No Consolidated Monitoring
These challenges may arise when there are multiple Azure Data Factories with different pipelines, data sources across various Subscriptions, Regions, and Tenants. Managing all of them using Azure Portal becomes cumbersome. To solve these critical challenges, Enterprise can leverage tools like the Azure Data Factory Monitoring in Turbo360.
Turbo360 is a one platform solution for Operation and Support Teams to efficiently manage and monitor Azure Serverless services.
Turbo360 offers,
- Application-level of Visibility
- Consolidated Monitoring
- Process Automation
- End to End Tracking
- Unified Azure Documentation
To know more:
Closing
In this blog, we learned why the Azure Data Factory is a key to migrate data across different data stores by creating pipelines and activities. In our upcoming blogs, we will talk more about Integration Runtimes, Data Flows, etc., Stay tuned to learn more!


