
For the past few months, I got hooked up with BizTalk360 and isolated myself from any deep technology learning. Now, BizTalk360 version 8.0 is out of my way the team is kind of settled down, I thought it’s time to look deep into some of the technology areas I was intending to learn for some time. As part of the process, I decided to put my foot first on Azure Event Hubs.
Azure Event hubs are not entirely new to me, I’ve been doing small bits and pieces here and there as hobby/prototype projects for a while. Now it’s time to understand a bit deeper into have various pieces fit together. I’ll try to cover my learning’s as much as possible in these blogs, so it might help people to get started.
What is Azure Event Hubs?
Before going into the technology side of things, let’s try to understand in layman terms why do we need this technology. The cloud consumption is getting more and more in many organizations, and there is a lot of new breed to Software as a Service (SaaS) solutions popping up every day. One of the common patterns you’ll see in the cloud adoption is how you are going to move data (either from on-premise or devices) into the cloud. Let’s take an example, you have some kind of monitoring service that monitors your server CPU utilization every 5 seconds, and you wanted to push this information to the cloud and store it in a persistent store like SQL Azure, MongoDB, Blob so on.
The traditional way of implementing this solution will be, you would have written some kind of web service (ex: ASP.NET WebAPI), deployed it into the cloud (as web role or VM’s) and you would have constantly fired messages to that WebAPI endpoint. It may initially sound easy to implement such a solution, but over a period once you start to scale (ex: you wanted to monitor CPU utilization in 1000’s of servers) then building the robustness and reliability of that web API endpoint solution will become complex. In addition, you can imagine the cost implications of setting up such infrastructure.
This is the exact problem Azure Event Hubs is going to solve for us. You simply provision event hub using the portal, which will give you the endpoints, and you can start firing the messages to that endpoint either via HTTPS or AMQP, the collected (ingested) data will get stored in EventHubs, then you can later read it using readers at your own phase. The data is retained for a period of time automatically.
What Is Azure Event Hub Used For?
Azure Event Hubs are designed for scale, it can process millions and millions of messages on both directions – inbound and outbound. Some of the real-world use cases include getting telemetry data from cars, games, application, IoT scenarios where millions of devices push data to the cloud, gaming scenarios where you push user activities at scale to the cloud, etc. There are tons of use cases why we need technology like Azure Event Hubs.
What is Event Hub Namespace in Azure?
Azure Event hub is kind of a roof under which we create number of Event hubs. A simple example is considering your organisation has multiple application that uses event hub. So, to segregate the event hubs more effectively, we can create one event hub namespace for each application and create the respective event hubs under the corresponding event hug namespace representing the application.
How does Event Hub Work?
Event Hubs uses a partitioned consumer model, enabling multiple applications to process the stream concurrently and letting you control the speed of processing.
Understand the building blocks
Let’s take a quick look at the top level architecture of Azure Event hubs and try to understand all the building blocks that make it powerful.
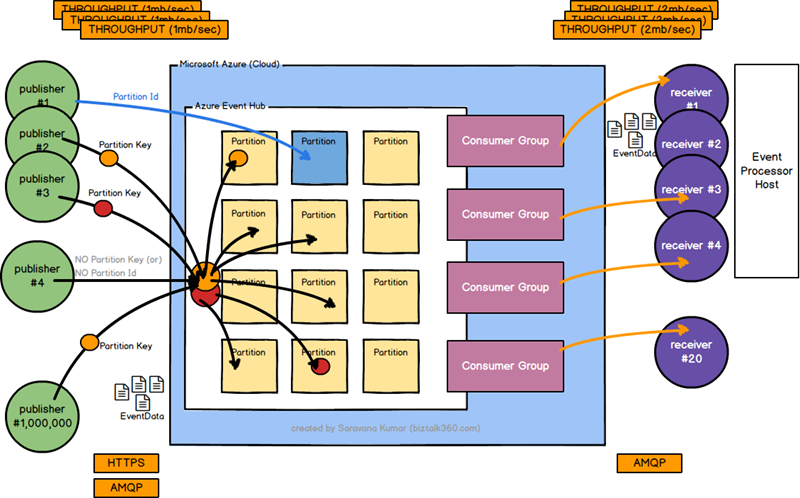
There are the important terminologies we need to learn when it comes to Azure Event Hubs
- EventData (message)
- Publishers (or producers)
- Partitions
- Partition Keys / Partition Id
- Receivers (or consumer)
- Consumer Groups
- Event Processor Host
- Transport Protocol (HTTP, AMQP)
- Throughput Units
There is also a security aspect which we will cover later.
Event Data
In the context of event hubs, messages are referred to as event data. Event data contains the body of the event which is a binary stream (you can place any binary content like serialized JSON, XML, etc), a user-defined property bag (name-value pair) and various system metadata about the event like offset in the partition, and it’s number in the stream sequence.
EventData class is included in the .NET Azure Service Bus client library. It has the same sender model (BrokeredMessage) used in Service Bus queues and topics at the protocol level.
Publishers (or producer)
Any entity that sends events (messages) to an Event Hub is a publisher. Event publishers can publish events using either HTTPS or AMQP protocol. For a simple scenario where your volume of published events are low, you can choose HTTPs, if you are dealing with high volume publishing then AMQP will give you better performance, latency, and throughput. Event publishers use Shared Access Signature (SAS) token to identify themselves to an Event Hub, they can have a unique identity or use a common SAS token depending on the requirements of the scenario (we will cover security separately).
You can publish events individually or batch. A single publication whether it’s an individual event or batched event has a maximum size limit of 256kb. Publishing events larger than this will result in an exception (quota exceeded).
Publishing events with a .NET client using the Azure Service Bus client library is just 3 lines of code

Publishing a batch of events at one go

Partitions
As you can see from the image, there are a lot of partitions inside an event hub. Partitions are one of the key differentiation in the way the data is stored and retrieved compared to other Service Bus technologies like Queue and Topics. The traditional Queue and Topics are designed based on the “Competing Consumer” pattern in which each consumer attempts to read from the same queue (imagine a single lane road, where the vehicles go one after the other, and there is no option to overtake), whereas Event hubs are designed based on “Partitioned consumer pattern” (think of it like parallel lanes in motorways, where traffic flows through multiple lanes, if one lane is busy vehicles choose another lane to move fast). The single lane queue model will ultimately result in scale limits, hence event hubs use partitioned consumer pattern to achieve the massive scale required.
The other important difference between normal Queue and Event Hub partitions is, in the Queues once the message is read it’s taken out of the queue and it’s not available (if there are errors, it will move to dead letter queue), whereas in Event hubs partitions the data in the partition stays there even after it’s been read by the consumer. This allows the consumers to come and read the data again if required (example lost connection). The events stored in partitions get deleted only after the retention period is expired (example 1 day). You cannot manually delete data from partitions.
The events get stored in the partition in sequence, as the newer events arrive they are added to the end of the sequence (more or less like how events get added to queues).

Event hub uses different sender usage patterns,
- A publisher can target the event data to a specific partition using a partition-id
- Group of publishers can use a common hash (PartitionKey) for automatic hash-based distribution
- Automatic random distribution using round-robin mechanism if the publisher didn’t specify any PartitionKey or Partition Id
Due to the varying distribution patterns, the partitions will all grow in different sizes from one another. It’s also important to know your event data will live in only one partition, it will not get duplicated. Partitions underneath have private blob storage managed by Azure.
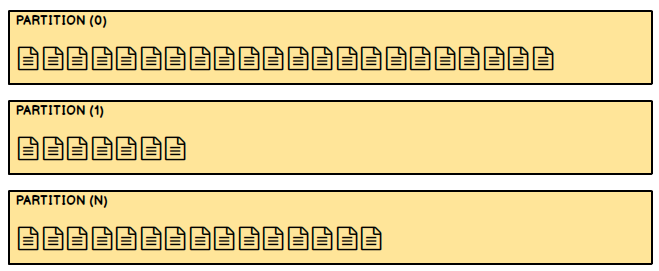
How Many Partitions Will a New Event Hub Have?
The number of partitions specified at the event hub creation time is static and it cannot be modified later (so care should be taken). Using the standard Azure portal you can create between 2 to 32 partitions (default 4), however, if required, you can create up to 1024 partitions by contacting Azure support.
What Is Partition Count in Event Hub?
Partition count represents the total number of partitions an event hub has. This must be provided while creation of the event hub and cannot be changed later.
Partition Keys / Partition Ids
In the main image, you can see the concepts of partition keys (represented as red and orange dots). The partition key is the value you pass in the event data for the purpose of event organization (grouping and making sure they live in the same place). There may be a requirement you wanted to move data from all the servers in a particular data center to get stored in a specific partition. If you note carefully, the event published has no knowledge about the actual partition, they simply specify a partition key and the event hubs make sure the keys with the same partition key are stored in the same partition. This decoupling of key and partition insulates the sender from needing to know too much about the downstream processing and storage of events.
If you do not specify the partition keys, event hub will just store incoming events in a different partition on the round-robin basis.

You can also send the event data directly to specific partitions if required. This is generally not a good practice you should either leave the publishing of events to event hubs in round-robin model, or you can take advantage of the PartitionKeys concepts as explained above, which is a bit more abstract and event hub will take care of grouping them together in relevant partitions.
However, if you have some special needs and want to write events to particular partitions, then you can do so easily by using the partition id as shown in the below code snippet.

Receivers (or consumers)
Any entity (applications) that read event data from an Event Hub is a receiver (or consumer). You can view from the main diagram above there can be multiple receivers for the same event hub, they can read the same partition data at their own pace. There is also an important thing to note, event consumers connect only via AMQP (whereas in the receive side we have both HTTPS and AMQP), this is because the events are pushed to the consumer from event hub via the AMQP channel, the client does not need to pull for data availability. This model is important both for scalability purposes as well as to avoid each consumers writing their own logic for checking new data availability and putting unnecessary load on the platform.
Consumer Groups
The data stored in your event hub (in all partitions) are not going to change, once it got stored in a partition they are going to live there until the retention period is elapsed (in which case the event data will be deleted). The data can be consumed (or read) by different consumers (applications) based on their own requirements. Some consumers want to read it carefully only once, some consumers may go back and read historical data again and again.
You can see there are varying requirements for each consumer, in order to support this, event hub uses consumer groups. A consumer group is simply a view of the data in the entire event hub. The data in the event hub can only be accessed via the consumer group, you cannot access the partitions directly to fetch the data. When you create an event hub, a default consumer group is also created. Azure also uses consumer group as differentiating factor between multiple pricing tiers (on the Basic tier you cannot have more than 1 consumer group, whereas in the Standard tier you can have up to 20 consumer groups)
Event Processor Host / Direct Receivers (Event Hub Receiver)
Event hubs primarily provide two different ways you can consume events. Either using the direct receivers or via a higher-level abstracted, intelligent host/agent called “Event Processor Host”
When you are building your receivers (consumers) to access the event data from the Event hub via the consumer groups, there are a bunch of things you need to take care of as a consumer responsibility. This will include things like
- Acquiring and Renewing Leases
- Maintaining offset, checkpoints and leader election handling (Epoch), and
- Thread safety
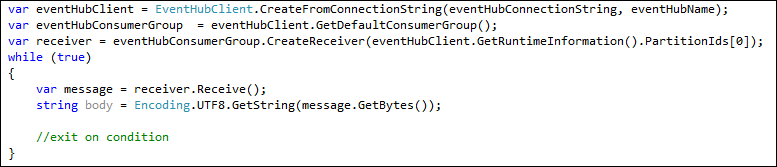
If you are going down building your own Direct Receivers, you need to manually take care of all the above points. Your code will look something like this
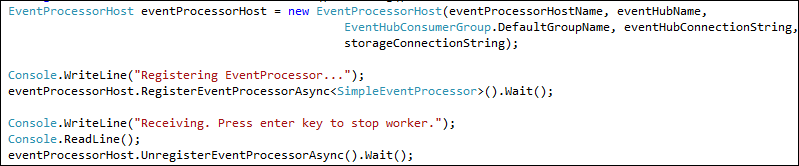
this is going to be a repeated task for every customer and it will require a level of knowledge to write the receivers in an efficient way. To address this challenge, Azure Event Hubs comes with a higher level abstracted intelligent host/agent called “Event Processor Host”, you simply implement the IEventProcessor interface and 3 core methods OpenAsync, ProcessEventsAsync, and CloseAsync. It takes an Azure blob parameter to manage offset/checkpoint against various partitions. This is the simplest way to consume events from event hubs. The new code will look like

Transport Protocols (HTTPs/AMQP)
From the main picture from the beginning, you can see there are 2 different types of transport protocols used for communications with Event Hubs. On the publisher (receiver) side, you can either use HTTPs if you are going to push a low volume of events to the event hubs, or you can use AMQP for high throughput, better performance scenarios.
On the consuming side, since event hubs use a push-based model to push events to listeners/receivers, AMQP is the only option.
Throughput Units
Throughput units are basics of how you can scale the traffic coming in and going out of Event Hubs. It is one of the key pricing parameters and purchased at event hub namespaces level and are applicable to all the event hubs in a given names space.
The other important thing to keep in mind is a single partition can scale to only one throughput unit, so it makes sense to have less number of throughput units than the total number of partitions you have. Example
- Namespace: IOTRECEIVER
- Event Hub #1: 4 partitions
- Event Hub #2: 2 partitions
In the above case, there is no point in having more than 6 throughput units for the namespace IOTRECEIVER. You probably need only 1 or 2 throughput units, unless otherwise, you have a huge volume of traffic.
Throughput units handle 1mb or 1000 events (event data) per second on the publishing side and 2mb/second on the consuming side. Think of throughput units like pipes, if you need more water to flow through, you get more pipes. The circumference of the pipe is fixed it can only take so much water. So if you either need to fill the tank or take more water is the only way to do it is by adding/fixing more pipes. Every pipe you add is going to cost you money.
Is Azure Event Hub Free?
There are free Azure Subscription that we can use. But those are very limited in terms of usage. Azure Event hubs are billed for its usage based on the capacity unit of the event hub.
Summary
Now we covered all the building blocks we saw in the original picture at the beginning of the article. Hopefully, this article would have given you all the bits and pieces requires to understand Azure Event Hubs. There are still a few topics I would like to cover that includes a security mechanism, metrics data, and many more. I’ll hopefully try to cover them in future articles.


