Many organizations are investing heavily in the data space, and Azure Synapse is one of the technologies in the Microsoft stack which is very popular. Within Synapse, Data Flows are the component of Synapse used to orchestrate the movement of data into and out of your Data Lake and for orchestrating jobs within your Data Platform.
The business heavily depends on your data platform for movements of data within the organization and the analytics-driven from data via Synapse. The challenge, however, is the same old problem that your Data Platform is like a black box that your technology experts can only manage, so you have a bottleneck when someone wants to know if everything is working, how things are running, etc.
With Turbo360, there is an opportunity to leverage the Business Activity Monitoring feature to open up the black box and provide visibility of those critical data flows and orchestrations in an easy-to-digest form, allowing non-experts to see what is going on safely and securely. This visibility will drive confidence in your Data Platform and help it become a key and popular asset to your organization.
In this post, we wanted to demonstrate how you can use BAM from a Synapse Pipeline to help democratize your Data Platform and give users and non-Synapse experts visibility
Azure Synapse Pipeline Data Flow
In this scenario, I have an application database for my rail car management system, which records railcars, what’s in them, and where they are at any time.
I need to pull this data into Synapse to merge it with data from other systems and analyze it in Power BI.
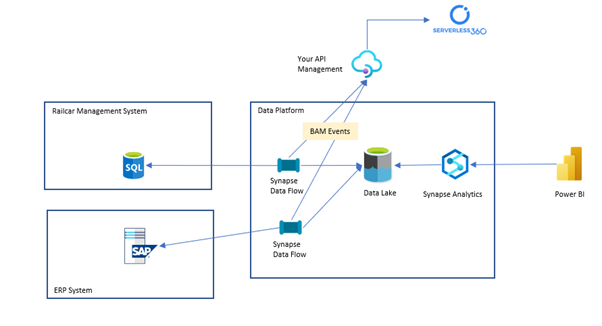
The solution will look something like the below.
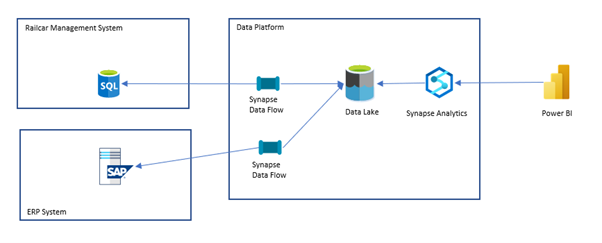
In this scenario, we have some data flow pipelines which pull data into the data lake, and then Synapse can query them, and the analytics is served in Power BI.
For this post, we will look at the area in the red box.
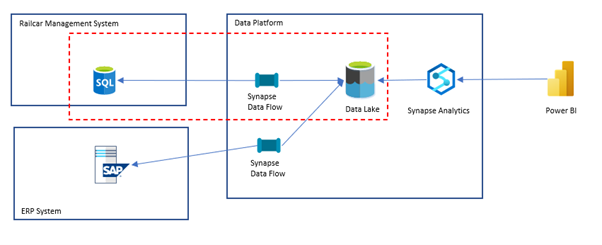
The data flow pipeline is the thing we want to create visibility for. We will look at how we can implement BAM in the pipeline to track the processing of this crucial business process without being a Synapse expert.
BAM Design Time
To start with, we need to implement a Business Process and Transaction within Turbo360 BAM, which will be used to represent our data flow.
When you are looking at using BAM in this context, you could have a BAM process that covers multiple data flows or single ones. BAM is the simplified logical representation of distributed tracing and does not have to match the physical implementation precisely. BAM is about creating a friendly and easily understandable view.
I assume you are already slightly familiar with building a business process and transaction for BAM. Please refer to this page for more info on Azure APIM as a proxy for Turbo360 BAM.
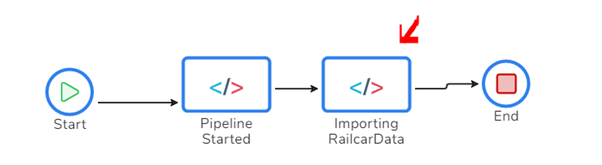
In the below picture, you can see I have added a business process for my Synapse demo, and I have added a transaction called “Copy Railcar Data to Synapse.”
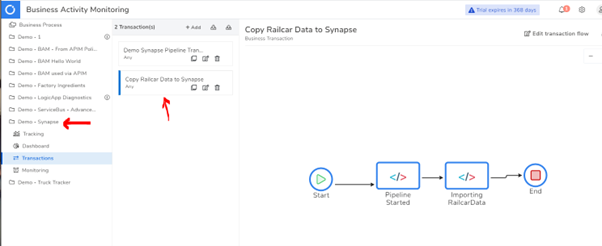
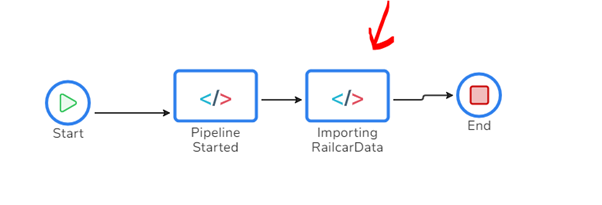
In the design for your BAM transaction, you can add shapes to the designer to represent the high-level milestones within the complex data flow. You can see this below.
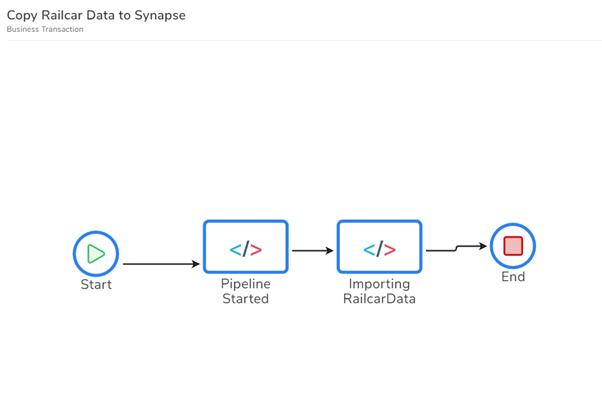
In this case, we will have a pipeline started milestone, and we will then begin the Importing Railcar Data milestone, which may run for a few mins, and then we will complete it and the transaction.
It will take a few minutes to set up, and you have your BAM transaction ready.
Implement BAM in Synapse Pipeline
Next, we need to go to Synapse and modify our pipeline to include BAM. In this case, we will start with a primary copy data pipeline generated from the Copy Data Tool. The pipeline looks like the below picture.
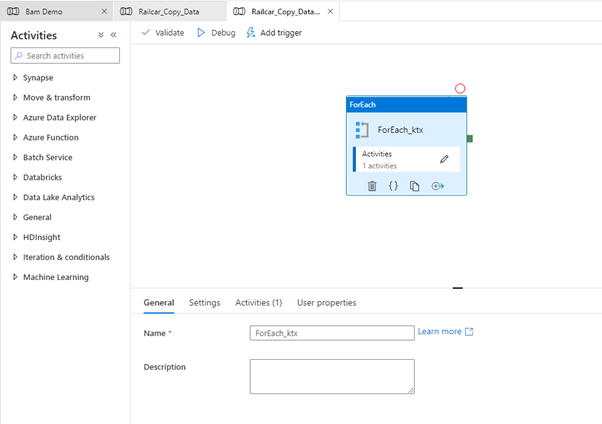
When it runs, it will go a for each and copy three tables into my data lake.
If I want to add BAM to my data flow pipeline, we can use the Web Activity to make an HTTP call to BAM, and we will end up with some shapes like the below.
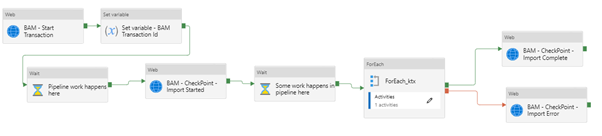
Calling BAM API
If you want to call the BAM API from your data flow, it’s as easy as an HTTP call. You will need to supply the URL, some headers, a security key, and a body that maps to your BAM business process, transaction, and milestone stage.
You can call the BAM API directly and get the settings from your BAM configuration settings, as shown below.
The alternative, and also the way id expect many customers to implement this in the real world, would be to connect their internal Azure API Management to the BAM API. Then they can share access to the API with multiple teams within their organization but centrally manage access control and usage.
It would look like the below:
Regardless of which way you implement the pattern, from the perspective of the Data Flow, it’s just a different URL and API key that would be used. In previous articles, we discussed this APIM proxy approach Azure APIM as a proxy for Turbo360 BAM.
Pipeline Variables
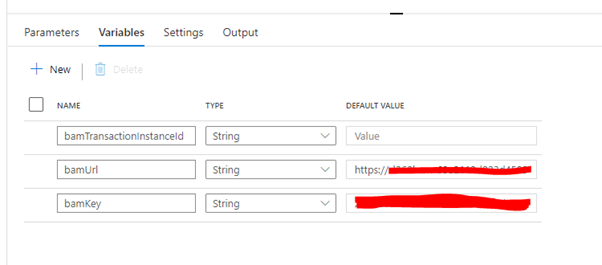
If we come back to the pipeline, we will start by needing to add some variables (or parameters) for your pipeline.
I created three variables:
- bamUrl will be the url for the BAM API
- bamKey will be the API key for my BAM API
- bamTransactionInstanceId will be to hold the guid returned by BAM when I start the transaction.
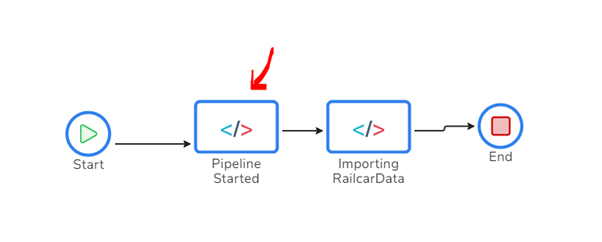
Start Transaction
In the pipeline, the first activity I added is a web activity that will call the BAM API to start a transaction. When this activity executes, it will point to the pipeline began milestone within the BAM diagram and mark it as green to show where we are in the process.
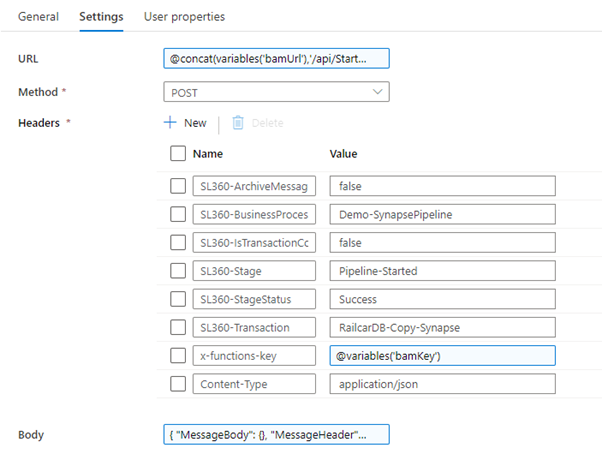
I will pass in the properties shown below:
|
Property |
Value |
Note |
|
URL |
@concat(variables(‘bamUrl’),’/api/StartTransaction’) |
I am concatenating the bam URL with the route for the StartTransaction operation. |
|
Method |
POST |
Headers
I am passing the following HTTP headers:
|
Name |
Value |
Note |
|
SL360-ArchiveMessage |
False |
True/false indicating if you want to archive the message body |
|
SL360-BusinessProcess |
Demo-SynapsePipeline |
Tracking id for the business process when you set it up |
|
SL360-Transaction |
RailcarDB-Copy-Synapse |
Tracking id for the BAM transaction when you set it up in Turbo360 |
|
SL360-Stage |
Pipeline-Started |
Tracking id for the stage in the BAM designer when you set up the transaction in Turbo360 |
|
SL360-StageStatus |
Success |
It will inform BAM this stage was successful |
|
SL360-IsTransactionComplete |
False |
Indicates the transaction is still running |
|
Content-Type |
application/JSON |
|
|
x-functions-key |
The critical variable in the pipeline |
Note if you use APIM as a proxy, you will pass the APIM key here instead |
Body
The body for the request needs to, at a minimum, be the JSON value below. It’s a JSON object with a message body and message header section.
{
"MessageBody": {},
"MessageHeader": {
}
}
You can populate the headers with a key-value pair of properties BAM can capture and promote to be searchable. You might consider passing things like the pipeline name, id, or custom values.
When the pipeline runs, this activity will start the transaction in BAM.
BAM Transaction Instance Id
The next activity in the pipeline was a Set-Variable. It will take the response from the Start Transaction web activity, and it will extract from the response the TransactionInstanceId property in the JSON response, which we will use when we call other BAM milestones to link them all together.
I created the bamTransactionInstanceId variable at the pipeline level earlier, and we will point this set variable activity to that variable and use the following expression.
@activity('BAM - Start Transaction').output['TransactionInstanceId']
Import Started CheckPoint
Next, we are about to start the long-running import process. At this point, I have decided to tell BAM that I am at a checkpoint I have called “Importing Railcar Data.” I will tell BAM that this checkpoint has started, but I expect it to take a little while, so ill come back later and mark it as complete.
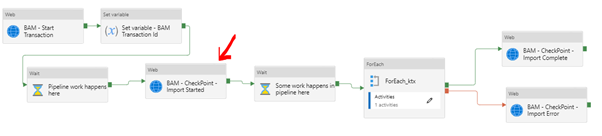
To set this checkpoint, we use another web activity in your pipeline. In the case of my demo, it’s pretty simple, but in the real world, you might have some work happening in the pipeline before you get to this checkpoint. Maybe you look up some metadata or similar.
In the pipeline, I am now at this point.
This shape is similar to the previous activity for doing the call to start the transaction. The differences are:
- The URL is not the same
The route is to the CheckPoint operation rather than start transaction, so I use the below expression
@concat(variables('bamUrl'),'/api/CheckPoint')
- The headers are different
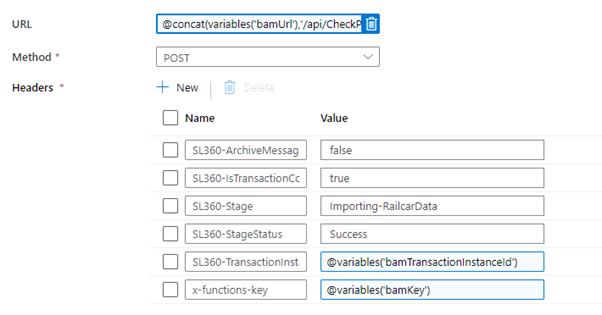
I do not need to supply the SL360-BusinessProcess or SL360-Transaction headers. I pass the SL360-TransactionInstanceId header and use the value from the guid we retrieved from the start transaction response.
I am also setting In Progress as the value for the SL360-StageStatus header.
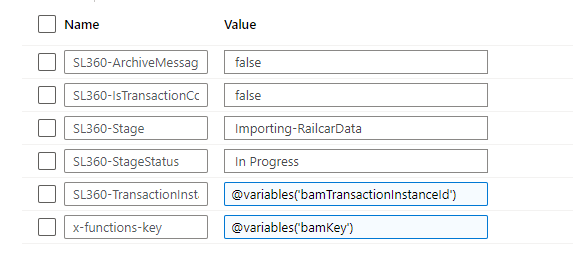
- The body can be different if you want
In my case, I’m just using the same body as earlier, but you can send a different payload if you want to tell BAM about some new or changed metadata.
Simulating Some work Happening
Next in the pipeline, I call the foreach, which will iterate over the configured tables for the import and copy them from my SQL database to the Data Lake.
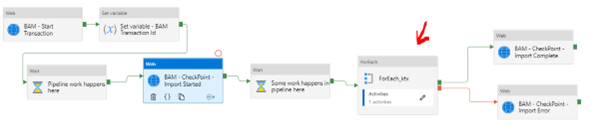
Completing the Transaction
The final stage in the pipeline tells BAM that the transaction is completed. It marks the Importing RailcarData stage as either successful or failed. When we did the checkpoint earlier to set the Importing RailcarData stage to In Progress, it will show as orange in the BAM runtime view until it is updated to Success or Failure.
In the pipeline, I have set 2 web activities to update BAM. Using the output lines from the ForEach, one will execute in a success condition, and one will execute in a failure.
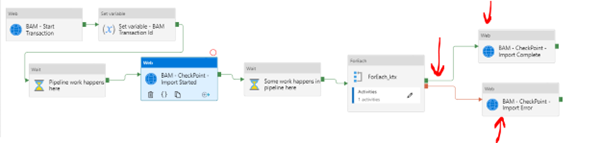
The only difference between these two shapes is that one sets the Header SL360-StageStatus to Failure and one to Success.
Both of them use the same URL as the previous step to do a checkpoint with the below expression:
@concat(variables('bamUrl'),'/api/CheckPoint')
You can see the below properties for the headers from the success activity:
Running the Data Flow
I have set up my activity to run on a recurring schedule at 8 am each day, like a typically scheduled import to the data lake. If we go to Synapse, we can see in the demo that we have the pipeline run completed.
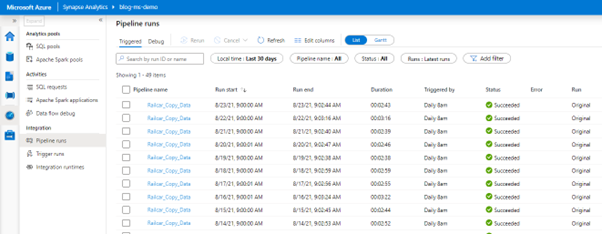
And we can see in the pipeline history the visual shows us the pipeline execution.
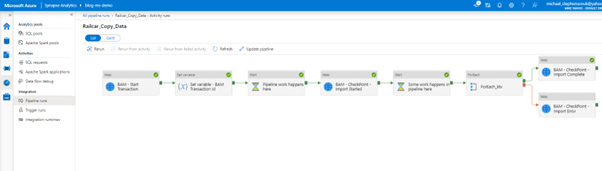
I am returning to the core problem that I need to be a Synapse expert to see this view and to be able to interpret what is happening. Here, BAM comes into the solution to provide a simplified, user-friendly view of the complex implementation.
BAM Runtime Tracking
In the BAM runtime view, I can now see the tracking data each time my pipeline runs. Below you can see the runs for the last few days.
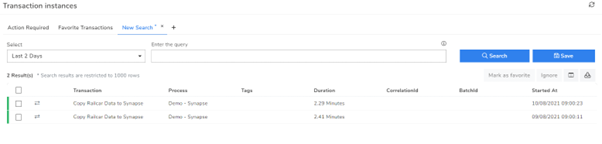
I can quickly tell they were successful, and any that failed would appear here as red on the left-hand side.
If I had sent any custom MessageHeaders from any web activities, I would have the ability to promote that data as searchable columns in the BAM view. An example might be that you promote a specific application property or similar. You can then search for transactions that match that value.
If I click on one of the transactions in the grid, I can open it up, and it will show me the process diagram, and I can see from the key which stages were successful.
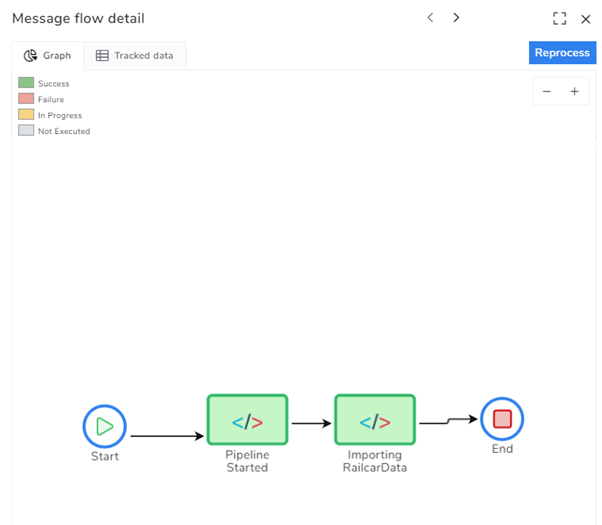
If we had sent any metadata or body with the checkpoint actions, we can click on the stages in the BAM diagram and see them.
Other BAM Features
There are several other great features in BAM that you now start opening up for potential users, such as:
- Action Required can help you keep on top of managing when issues might have happened and ensuring you have sorted them out
- Reprocessing can let you a way to allow the non-expert potentially replay an action
- Dashboards can help you get a holistic view of performance and processing across your BAM process
You can find out more about our BAM features in the section of our documentation here.
Conclusion
I hope this article will show how you can use BAM to help you achieve distributed tracing and improve the visibility and manageability of your data platform processes which you are implementing with Synapse data flows.
We aim to help lower the total cost of ownership through the democratization of support for your solution and improve your users’ experience and confidence in the solution, which will encourage further investment in your platform.
Try BAM
If you want to explore how BAM can help you implement interfaces that integrate with SAP or other systems using the Microsoft Integration Services, go to the Turbo360 Azure Distributed Tracing Tool for more info and a trial.


