
When architecting a solution in Azure, it is always important to keep in mind any limitations which might apply. These limitations can come not only from tier choice but also from technical restrictions. Here, we will have a look at the Service Bus throttling conditions, and how to handle them. When you are at the documentation page, it is clear there are several thresholds which will affect the maximum throughput achieved before running into throttling conditions.
- Queue/topic size
- Number of concurrent connections on a namespace
- Number of concurrent receive requests on a queue/topic/subscription entity
- Message size for a queue/topic/subscription entity
- Number of messages per transaction

Azure Service Bus Throttling conditions
Each of these conditions has their characteristics and ways in which to handle them when they occur. It is important to understand each, as it allows us to take decisions on the following steps. And, set up a resilient architecture to minimize risks. Let us have a look at each and at the options to mitigate these thresholds.
Queue/topic size
This threshold stands for the maximum size of a Service Bus entity and defined when creating the queue or topic. When messages are not retrieved from the entity or retrieved slower than they are sent in. The entity will fill until it reaches this size. Once the entity hits this limit, it will reject new incoming messages and throws a QuotaExceededException exception back to the sender. Maximum entity size can be 1, 2, 3, 4 or 5 GB for the basic or standard tier without partitioning. 80GB standard tier with partitioning enabled as well as for the premium tier.
When this occurs, one option is to add more message receivers, to ensure our entity can keep up with the ingested messages. If the entity is not under our control, another option would be to catch the exception, and use an exponential backoff retry mechanism. By implementing an exponential backoff, receivers get a chance to catch up with processing the messages in the queue. Another option is to have the receivers use prefetching, which allows higher throughput, clearing the messages in our entity at a faster rate.
Number of concurrent connections on a namespace
The second threshold discussed in this post is about the number of connections allowed to be open simultaneously to a Service Bus namespace. Once all of these are in use, our entity will reject subsequent connection requests, throwing a QuotaExceededException exception. To mitigate this condition it is essential to know that queues share their connections between senders and receivers. Topics, on the other hand, have a separate pool of connections for the senders and receivers. The protocol used for communication is also essential, as NetMessaging allows for 1000 connections, while AMQP gives us 5000 connections.
This means that as the owner of the entities, there is the possibility to switch from queues to topics, effectively doubling the number of connections. Beware though, this will only increase the number of total allowed connections, but if there is already a large number of senders or receivers, it will still just give us the maximum of connections the chosen protocol gives us for each of these. If the sender or receiver client is under our control, there is also the option to switch protocols, which could provide us with five times the amount of connections when switching from NetMessaging to AMQP.
Number of concurrent receive requests on a queue/topic/subscription entity
This threshold applies to the number of receive operations invoked on a Service Bus entity. Each of our entities has a maximum of 5000 receive requests it can handle concurrently. In case of topic subscriptions, all subscriptions of the topic share these receive operations. Once the entity reaches this limit, it will reject any following receive requests until the number of requests is lower and throws a ServerBusyException exception back to the receiver. To handle this limitation, once again the option is there to implement an exponential backoff retry strategy while receiving messages from our Service Bus entity. An alternative would be to lower the total number of receivers.
Message size for a queue/topic/subscription entity
Service Bus entities only allow for a limited size for their incoming brokered messages. When trying to send in larger messages, the entity rejects these and throws a MessageSizeExceededException exception back to the sender. For the basic and standard tier, the maximum message size is 256KB, while for the premium tier it is 1MB. When working with large messages, it is possible to split these and send the chunks over the line, re-assembling them on the receiver side. Another option is to implement a claim check pattern, in which case storage of the large payload is done at an alternative location and only a reference to this is sent in the brokered message.
Number of messages per transaction
When sending messages in transactions, the limit is 100 messages per transaction, both for synchronous and asynchronous calls. When trying to post more messages inside of a single transaction, the entity throws a TransactionSizeExceededException exception back to the sender and rejects the complete transaction. The answer to this restriction is making sure the calling code never exceeds 100 messages in a transaction.
Retries
For several of the throttling conditions doing retries is a plausible solution to ensure our client delivers its messages in the end. This is the case in any situation where time can help resolve the problem. The fix can be due to retrieval of messages, closing of connections, or the number of clients decreasing. However, it is important to note that retries will not help for all these throttling conditions. For example, when a message is too large, retrying this message will never result in success. Therefore, it is important to check the actual exception that you receive when catching these. Depending on the type of message, you can take decisions on the next steps.
Furthermore, by default retries will occur every 10 seconds. While this is acceptable for many occasions, it might be better to implement an exponential retry mechanism instead. This mechanism retries with an increasing interval, for example first after 10 seconds, then 30 seconds, then 1 minute, and so on. This mechanism allows for intermittent issues to resolve quickly. But also help on lasting exceptions thanks to the increasing interval between retries mitigates provided by an exponential backoff retry mechanism.
Monitoring
When working with Service Bus, it is crucial to implement a suitable monitoring strategy. There are several options to do this, ranging from the built-in tooling in Azure to using a third-party product like Turbo360. Each of these solutions has their strengths and weaknesses. When it comes to watching the Service Bus throttling state, Azure Monitor has recently added new metrics which allow us to do just that. These capabilities are currently in preview and gives several metrics to keep an eye on Service Bus namespaces and entities. One of these metrics is Throttled Requests, giving us insights into the number of requests throttled.
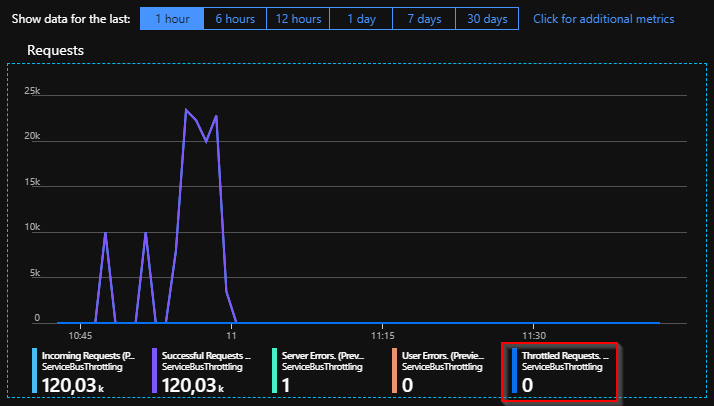
Subsequently, it is even possible to set up alerts on top of these metrics, which you can accomplish through Azure Monitor. Add an alert rule for this scenario. These rules define when to trigger alerts, and which actions to take.
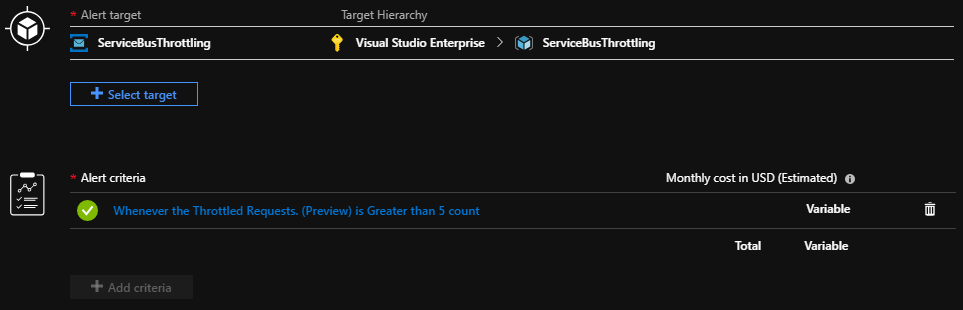
These actions range from sending out an email or SMS, all the way to calling webhooks or invoking Logic Apps. These latter options give us the possibility to start custom workflows, notifying specific teams, creating a ticket, and more like these. For this, specify an action group with one or more actions in the alert rule. Consequently, it is even possible to create multiple action groups can for different alert types. Here you can send high-level alerts to the operations team and service-specific alerts to the owners of that service within the organization.
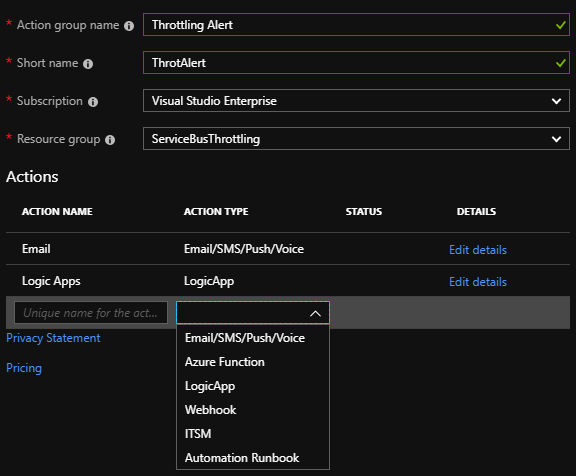
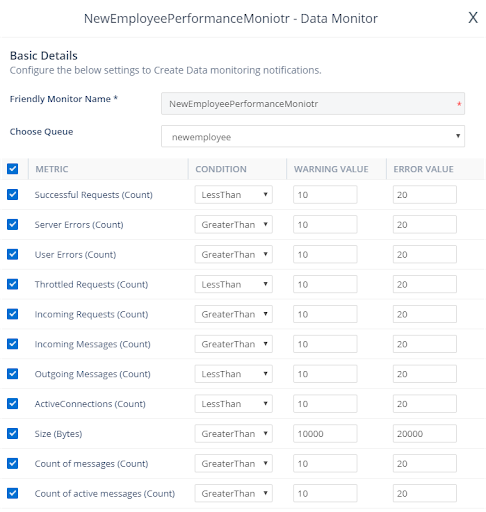
Turbo360 provides easy configuration and notification options for Azure service bus monitoring and raise alerts for Service Bus Throttling conditions.
Conclusion
When setting up an architecture with Azure services it is always important to keep an eye on the capabilities. In this case, we investigate Service Bus throttling conditions. Often, mitigation is done by adjusting some of the properties of our clients or implementing a retry strategy. Additionally, to keep clear insights into our environment, a monitoring strategy needs to be implemented for our situation. Where alerts are triggered in case any of these throttling conditions occur.

