
A few months ago, I wrote on my blog a post about “Processing Feedback Evaluations (paper) automagically with SmartDocumentor OCR, Microsoft Flow & Power BI” in which I create a Flow that process a speaker evaluation form and place the result on a Power BI dashboard to present in conferences.
Because I created this from a business user perspective, avoiding any custom code, to properly extract the data from the SmartDocumentor original message that is a Key/Value JSON message:
[{"Key":"RecognitionRating","Value":"95.5"},
{"Key":"RecognitionStatus","Value":"ToReview"},
{"Key":"ReviewsCount","Value":"0"},
{"Key":"ReviewedFields","Value":""},
{"Key":"OriginalFileHash","Value":""},
{"Key":"S1","Value":""},
{"Key":"S2","Value":"S2"},
{"Key":"S3","Value":""},
{"Key":"S4","Value":""},
{"Key":"Q1","Value":"8"},
{"Key":"Q2","Value":"9"},
{"Key":"Q3","Value":"5"},
{"Key":"Q4","Value":"7"},
{"Key":"EndUser","Value":""},
{"Key":"Developer","Value":""},
{"Key":"Designer","Value":""},
{"Key":"ScrumMaster","Value":""},
{"Key":"TeamLeader","Value":""},
{"Key":"Manager","Value":""},
{"Key":"Coach","Value":""},
{"Key":"Researcher","Value":""},
{"Key":"Educator","Value":""},
{"Key":"Name","Value":"CFYI - - -FCK "},
{"Key":"Company","Value":"LLZLLYC"},
{"Key":"Email","Value":""},
{"Key":"Telephone","Value":""},
{"Key":"Other","Value":""},
{"Key":"Consultant","Value":"Consultant"},
{"Key":"Student","Value":""},
{"Key":"Session","Value":"S2"}]
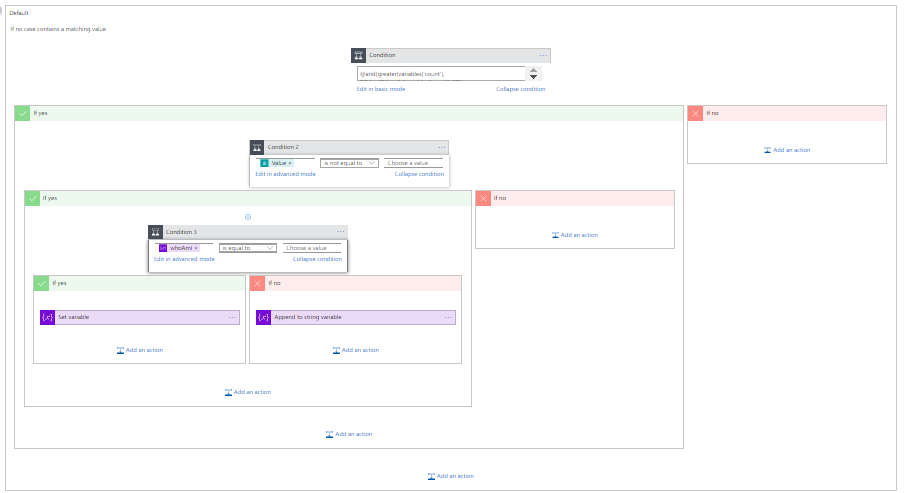
I had to create an insane amount of conditions inside a Switch operation.
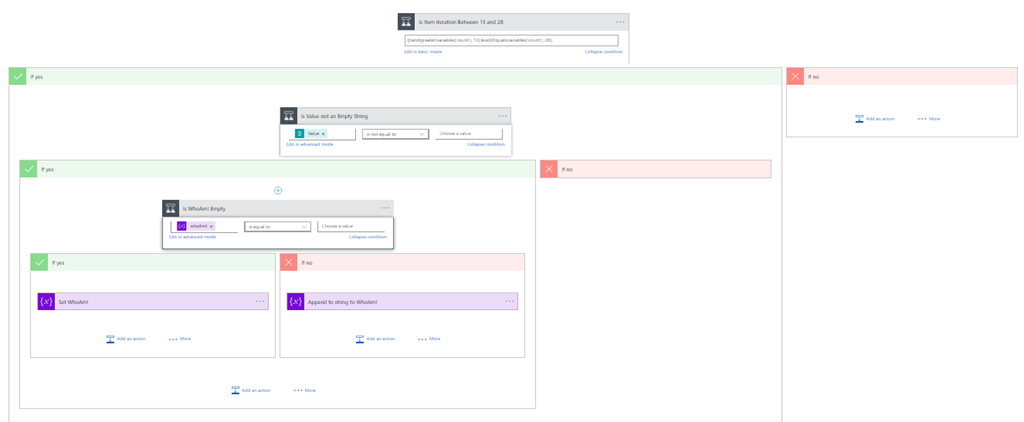
The picture above is just a little fragment of the conditions inside the Switch operation. Even reducing my browse resolution to the minimum, I cannot have the entire picture of all the conditions inside my Switch Operation.
The result regarding performance is that each speaker evaluation submission took 1 or more minutes to be processed:
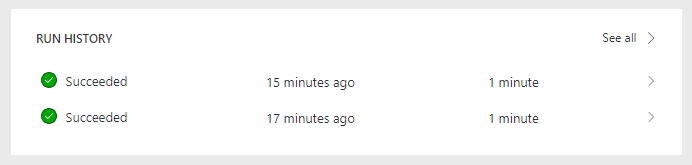
You may see in the history that it took one minute. But in reality, you will find the Switch operation had 31 iterations and it took 2 minutes to complete:
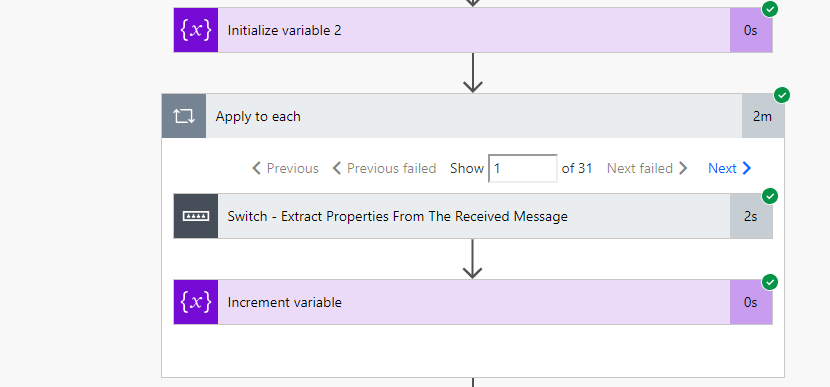
Is not bad, but if you are in a big conference and have an insane amount of evaluation to process you may be interested in optimizing your Flow to process faster the evaluation forms.
So, the critical question would be: how can we optimize your flow’s?
Two vital tips to optimize your flow performance are:
- To avoid at any cost having nested conditions inside a loop (Apply to each) as I have implemented on my Default branch inside the switch operation

- moreover, avoid at any cost having nested loop operations
I think these two situations are the most painful situations regarding performance.
Solution 1: Improving performance by reducing to 1 quarter of the initial time
So, as I told earlier, the massive amount of conditions, especially on the default branch, inside my Switch Operations was causing a significant impact on the performance of my Flow execution.
If you read my blog post, you will find out that those nested conditions were necessary to retrieve the profile of the attendee (“whoAmI”) that is a multiple option checkbox that appears on the JSON message from 13 to the 29 positions. So, to avoid this situation, I asked my internal SmartDocumentor OCR team to improve a little the incoming JSON message to have another record that includes the attendee profile combination.
{"Key":"AboutYou","Value":"Consultant;Developer"}
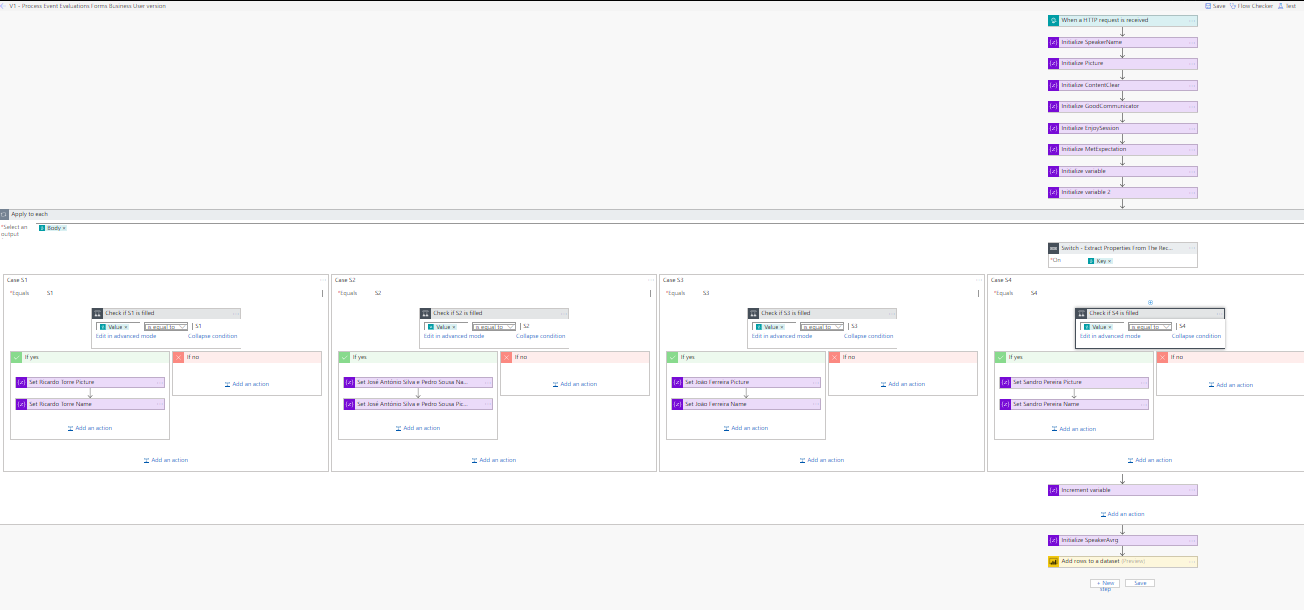
Because they were doing the OCR they were able to identify that and by having this small change to my incoming message I was able to replace my nested conditions inside the default branch by a simple Case branch:
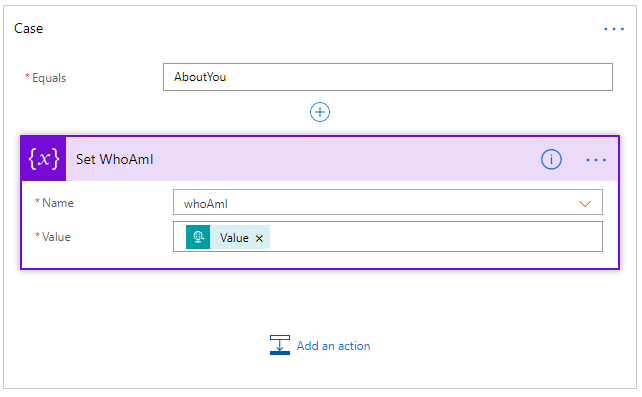
This strategy also enabled me to reduce the number of operations inside my flow. As I no longer need the “Count” variable, so I was able to delete:
- Set “Count” variable operation
- and Increase the“Count” variable operation
The result:
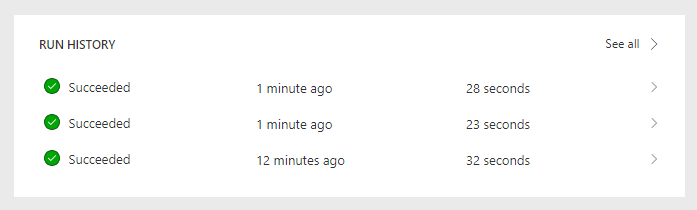
Wow! How a simple change on the input of a message can make a considerable difference of the end performance execution of your flow.
Another essential key learn is to optimize your messages to the proper input and output.
Solution 2: Improving performance to less than X second(s) Flow execution time
It is evident that the time-consuming task is to extract and map the incoming JSON message into the expected JSON message to be delivered to the Power BI action – Add rows to a dataset. This is what we call the messages transformation or mapping in enterprise integration.
To archive the best result regarding performance, I had to leave the Business User approach and enter in my developer mode and remove this transformation logic outside my Flow and implement it inside an Azure Function that:
- accepts my JSON Key/Value message sent by SmartDocumentor OCR;
#r "Newtonsoft.Json" using System; using System.Net; using Newtonsoft.Json; using Newtonsoft.Json.Linq; public static async Task Run(HttpRequestMessage req, TraceWriter log) { log.Info($"Webhook was triggered!"); string jsonContent = await req.Content.ReadAsStringAsync(); dynamic data = JsonConvert.DeserializeObject(jsonContent); string speakerName = string.Empty; string speakerPicture = string.Empty; int pos = 0; for(int i=5; i<=10; i++) { if(!String.IsNullOrEmpty(data[i]["Value"].Value)) { pos = i; break; } } switch (pos) { case 5: speakerName = "Nino Crudele"; speakerPicture = "https://blog.sandro-pereira.com/wp-content/uploads/2017/05/Nino-Crudele.png"; break; case 6: speakerName = "Sandro Pereira"; speakerPicture = "http://blog.sandro-pereira.com/wp-content/uploads/2017/03/Sandro-Pereira.png"; break; case 7: speakerName = "Steef-Jan Wiggers"; speakerPicture = "https://blog.sandro-pereira.com/wp-content/uploads/2017/05/Steef-Jan-Wiggers.png"; break; case 8: speakerName = "Tomasso Groenendijk"; speakerPicture = "https://blog.sandro-pereira.com/wp-content/uploads/2017/05/Tomasso-Groenendijk.png"; break; case 9: speakerName = "Ricardo Torre"; speakerPicture = "http://blog.sandro-pereira.com/wp-content/uploads/2017/03/RicardoTorre.png"; break; case 10: speakerName = "Eldert Grootenboer"; speakerPicture = "https://blog.sandro-pereira.com/wp-content/uploads/2017/05/Eldert-Grootenboer.png"; break; default: speakerName = "Unknown"; speakerPicture = "http://blog.sandro-pereira.com/wp-content/uploads/2017/03/devscope.png"; break; } string whoAmI = string.Empty; int first = 0; for(int i=16; i<=28; i++) { if(!String.IsNullOrEmpty(data[i]["Value"].Value)) { if (first == 0) { whoAmI = data[i]["Value"].Value; first = 1; } else{ whoAmI = whoAmI + ";" + data[i]["Value"].Value; } } } int result = 0; decimal avrg = (decimal)((int.TryParse(data[11]["Value"].Value, out result)?result:0) + (int.TryParse(data[12]["Value"].Value, out result)?result:0) + (int.TryParse(data[13]["Value"].Value, out result)?result:0) + (int.TryParse(data[14]["Value"].Value, out result)?result:0) + (int.TryParse(data[15]["Value"].Value, out result)?result:0)) / 5; JObject eval = new JObject( new JProperty("SpeakerName", speakerName), new JProperty("SpeakerPicture", speakerPicture), new JProperty("ContentClearFB", data[11]["Value"].Value), new JProperty("GoodCommunicatorFB", data[12]["Value"].Value), new JProperty("EnjoySessionFB", data[13]["Value"].Value), new JProperty("MetExpectationsFB", data[14]["Value"].Value), new JProperty("GainedInsightFB", data[15]["Value"].Value), new JProperty("SpeakerAvrg", avrg), new JProperty("WhoAmI", whoAmI)); log.Info($"Webhook was Complete!"); return req.CreateResponse(HttpStatusCode.OK, new { MsgEval = eval }); } - and return another JSON message with the required attributes for sending to Power BI
You may think that out-of-the-box there isn’t an Azure Functions connector and you are correct. Nevertheless, Azure Functions are available by HTTP so you can make use of the HTTP connector to call them:
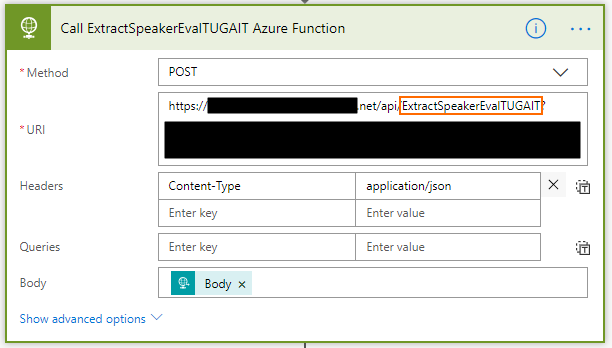
Then make use of the Parse JSON action to create the tokens to be used on the Power BI action.
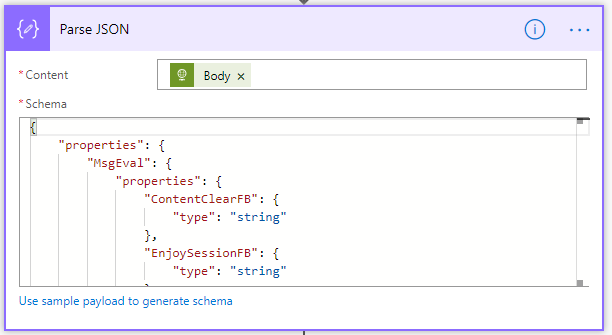
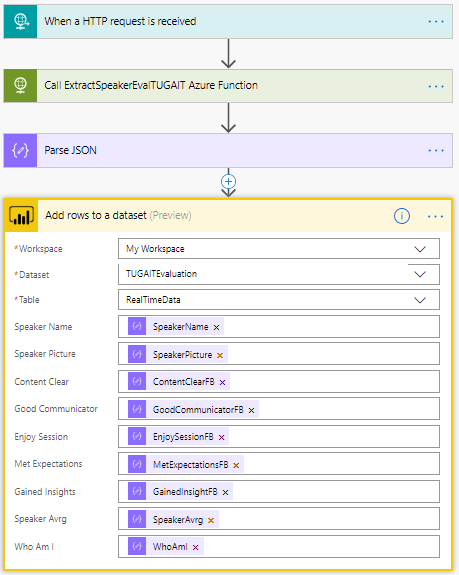
The end solution would be like this:
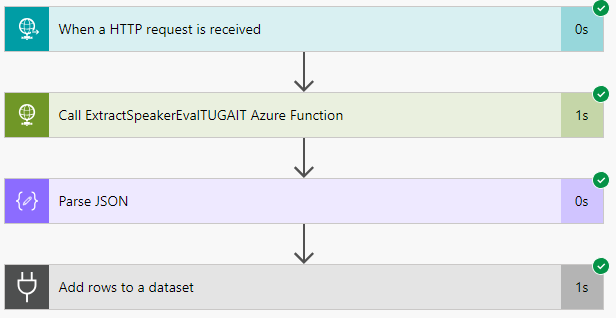
If you try the solution now, you will be amazed by the performance archived:
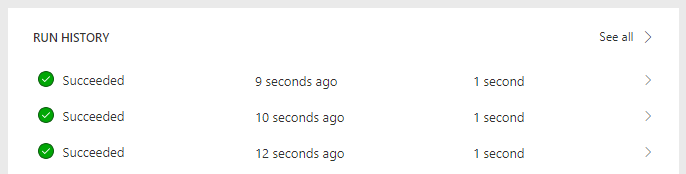
1-second average! WOW!
Lessons learned
These are some of the vital tips that you need to take into consideration while implementing your Flow’s:
- Avoid at any cost having nested conditions inside a loop (Apply to each);
- Avoid at any cost having nested loop operations;
- Optimize the structure of the input and output messages;
- Avoid doing message heavy transformations or extractions using standard Flow actions
- Move this logic to outside the Flow’s, Azure Functions are a good solution


