Azure Data Factory is a cloud-based data integration service that allows you to orchestrate and automate data movement and transformation using cloud-based data-driven workflows. It provides a cost-effective solution whenever a dependable code-free ETL tool on the cloud with numerous integrations is required.
This blog will highlight how users can use Turbo360 to manage and monitor multiple Azure Data Factories with different pipelines.
Azure Data Factory consists of a variety of components like:
- Pipeline is a logical grouping of activities that perform a task. It allows you to manage the activities as a set instead of each one individually. Ingesting data from the Storage Blob, querying the SQL Database, many other activities can be performed by a single pipeline.
- Activities in a pipeline represent a unit of work. It defines the actions on your data, like copying data from SQL Server to Azure Blob Storage.
- Linked services are connection strings that allow you to connect to the data stores.
- Datasets represent the data structures within the data stores that point to the data you want to use as inputs and outputs in your activities.
- Triggers are a method for executing a pipeline run. Triggers specify when the execution of a pipeline should begin. There are three types of triggers that Data Factory currently supports:
- Schedule trigger, a time-based trigger that invokes a pipeline at a scheduled time.
- The Tumbling window trigger operates on a periodic interval.
- An event-based trigger responds to an event.
- The Integration Runtime (IR) is the compute infrastructure that provides data integration capabilities like Data Flow, Data movement, Activity dispatch, and SSIS package execution. There are three types of Integration runtimes offered by Data Factory:
- Azure
- Self-hosted
- Azure SSIS
Azure Data Factory in Turbo360
Turbo360 is a single platform solution that enables Operations and Support Teams to manage and monitor Azure Serverless services more efficiently.
Turbo360 has the following capabilities for Azure Data Factory Monitoring:
Data Factory Pipelines
A pipeline run is an instance of a pipeline execution that could have been executed manually or on a trigger. Turbo360 offers the list of pipeline runs and the ability to search for a pipeline run based on its execution status, start time, and end time.
Triggering a pipeline and stopping a pipeline execution is possible with Turbo360.
Consider a scenario where a developer needs to migrate data from an Azure SQL database to another Azure SQL database for testing; it can be done with the help of a Data Factory Pipeline. Triggering the pipeline from Turbo360 will help in the data migration.
A pipeline run might fail due to failure in any of its activities, say; in this case, suppose a table in the source database is not found in the target database, the pipeline execution gets failed. In such cases of failed pipeline runs, there comes a need to re-run the particular run, and it is done at ease with Turbo360.
Turbo360 also allows you to see a list of all Trigger runs and Integration runtimes related to a specific Data Factory.
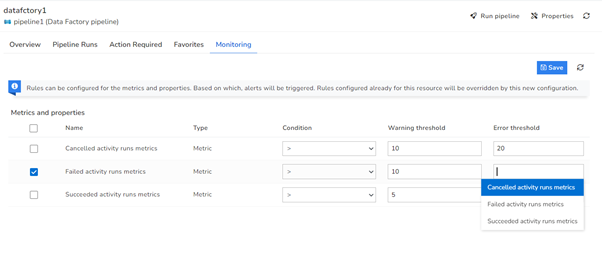
Monitor the Data Factory and its pipelines with the help of Turbo360. For example, suppose a monitoring requirement arises to receive alerts when the count of the failed activity runs of a pipeline exceeds a particular value. In that case, Turbo360’s Data Factory Pipeline monitoring comes into place.
What’s new?
- There are instances when it is necessary to know when the subsequent pipeline execution will begin. Turbo360 satisfies this requirement by providing a list of Triggers associated with each Data Factory Pipeline, as well as their recurrence details.
- Turbo360 has also devised a method of displaying a list of Integration runtimes associated with a specific Data Factory pipeline, allowing users to distinguish between pipelines that employ Self-Hosted Integration runtime (SHIR) and those that use the default Integration runtime.
- External values are typically passed into pipelines, datasets, linked services, and data flow via parameters. By parameterizing the Data Factory Pipeline, you can reuse the parameters with different values each time you execute the pipeline. Let’s take the same scenario: a developer needs to migrate data from one Azure SQL database to another. Consider that the pipeline takes the source and target databases as parameters. Turbo360 now extends the capability to trigger a Data Factory Pipeline by dynamically passing values to the already configured parameters of the pipeline without having to switch to Microsoft Azure. Trigger the pipeline with a distinct set of parameter values each time. When a parameterized pipeline run is re-run, the parameters of the original run is carried forward to its execution.
- Turbo360 also allows you to filter the resources in a Business Application by multiple fields.
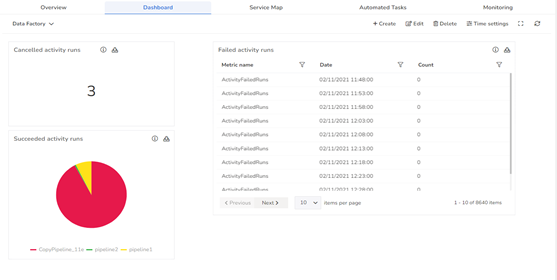
- The Dashboard service from Turbo360 allows for better data visualization and tracking of real-time data. Widget on Data Factory Pipeline will enable the grouping of different pipelines and tracking them based on various metrics. Consider the case when a Turbo360 user needs to retrieve data on the number of Failed activity runs of a given Data Factory Pipeline in a specific time window, say the previous 30 days, with 5-minute granularity. The data presented in the dashboard widget would now have great information. It would appear more effortless if the user could manually obtain a copy of the data to analyze it according to his needs. Turbo360 offers a superior approach by allowing users to download the widget data in Excel format.
Integration runtimes
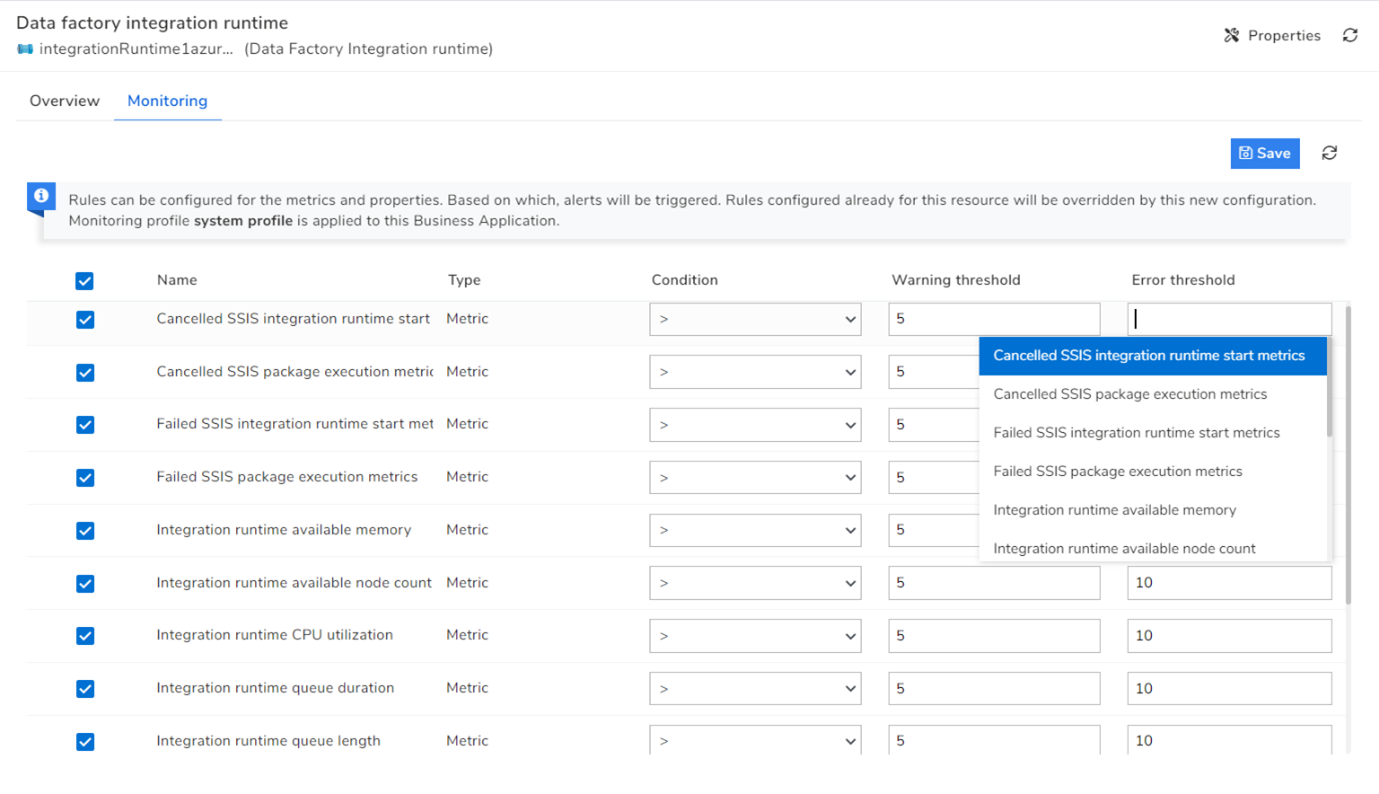
Apart from Azure Data Factory Pipelines, you can also manage and monitor the Integration runtimes from Turbo360. It is feasible to monitor an Integration runtime using a variety of metrics when it is associated with a Turbo360’s Business Application.
What’s new?
- Each Integration runtime associated with Turbo360’s Business Application now shows the number of nodes linked to it, as well as the node’s critical information. Turbo360 can now provide related information such as all the Linked services and Data Factory Pipelines to which the Integration runtime is connected.
Conclusion
This blog taught us how Turbo360’s management and monitoring features enhance Azure Data Factory. Stay connected to learn more about Turbo360’s capabilities in managing the Azure Serverless Services.


