This blog is a transcript of the session “High Availability and Disaster Recovery recipes for Azure Integration Services” presented by Toon Vinehout, a Belgian Microsoft Azure MVP.
Like on-premise scenarios, it is important to have your Azure Integration Services Highly Available. For many organizations, the integration backbone is the beating heart of the company. In such cases, downtime must be minimized as much as possible.
In this blog, we will see the aspects that are impacting your Recovery Point Objective (RPO) and Recovery Time Objective (RTO). Several high availability scenarios and disaster recovery options for Azure Integration Services will be explained. Let us see recipes for High Availability and Disaster Recovery.
Why is Availability Important?
There could be various causes. Well, in the end, it comes into costs.
- It might be your employees are not productive,
- Your customers might not able to use your online services, or not even able to post any orders
The average cost of 1-hour downtime = €311,000 (Gartner 2014)
So, availability is more important.
Cloud Availability: Service Level Agreement (SLA)
If you have a look at the Azure Integration Services downtime give it look pretty good. But when you start combining those individual services you need to think about composite SLA. When you combine all those down-time you will get 26 minutes downtime per week.
This downtime is not acceptable in many businesses. So how come you can improve your SLA?

Solution
SLA are Typically defined on per region basis when you spin your solutions across multiple regions will increase your availability drastically.
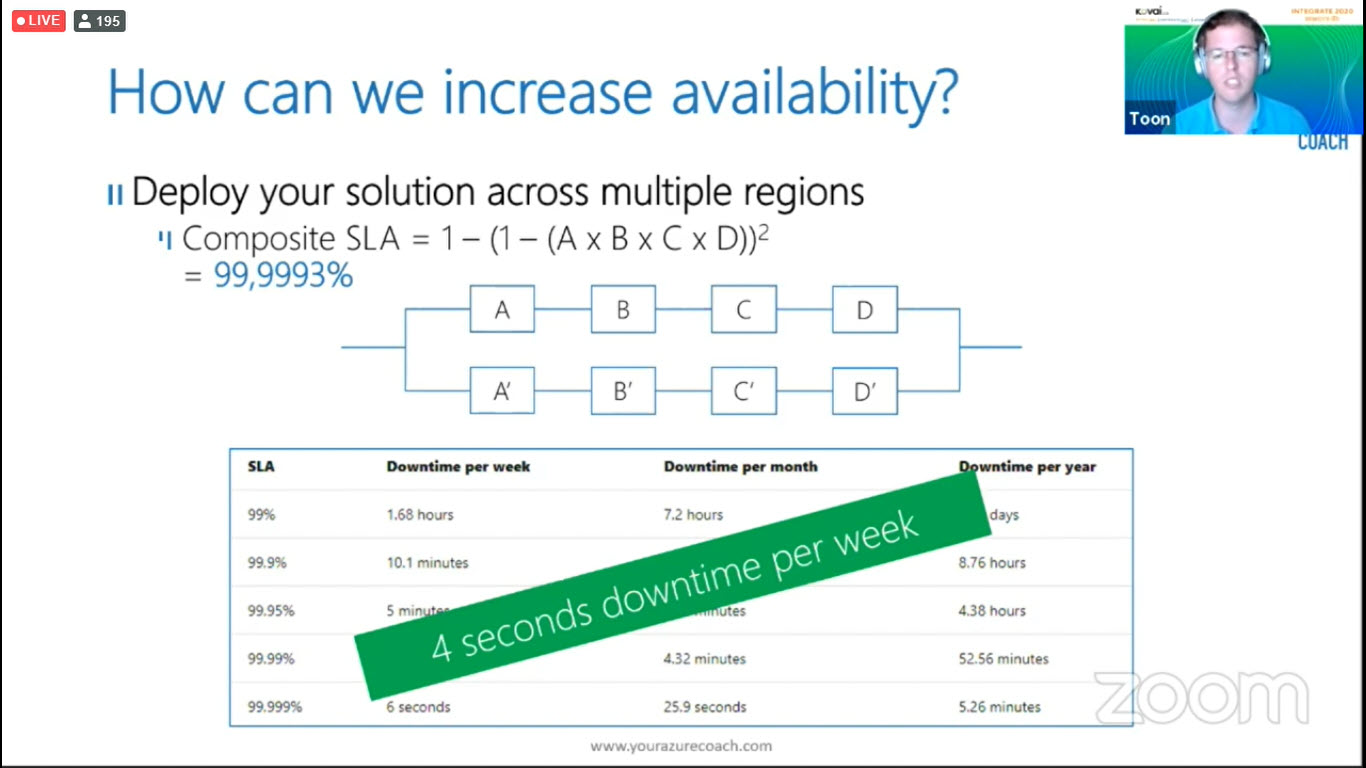
4 seconds downtime per week in any organization is acceptable.
Define the Right Strategy for Your Business
It is very important to define your strategy when you are using Azure Integration. In general, you need to analyze the available strategy for every quarter and refresh, to see if it is still valid.
HA Strategy
The first pillar of your strategy should be High Availability (HA). Every measure you make and take in normal circumstances to make sure you remove a single point of failure and implement redundancy. Let us see the tips,
- Wait and see – Relay on the HA of a single region
- Resiliency – Apply decoupling and resiliency
- Multi-region setup – Active-Active within paired regions
- Scope – Not all parts are business-critical
Disaster Recovery (DR) Strategy
Making sure that any incident (it can be an accident) occurs to get your system back in operation state. Let us see the options,
- Recreate environment – Redeploy after a disaster occurred
- Cold Stand-By – (Use CI-CD pipeline) Restore backups in the passive region
- Host Stand-By – Active replication to a passive region which is high cost.
- Scope – Not all parts are business-critical
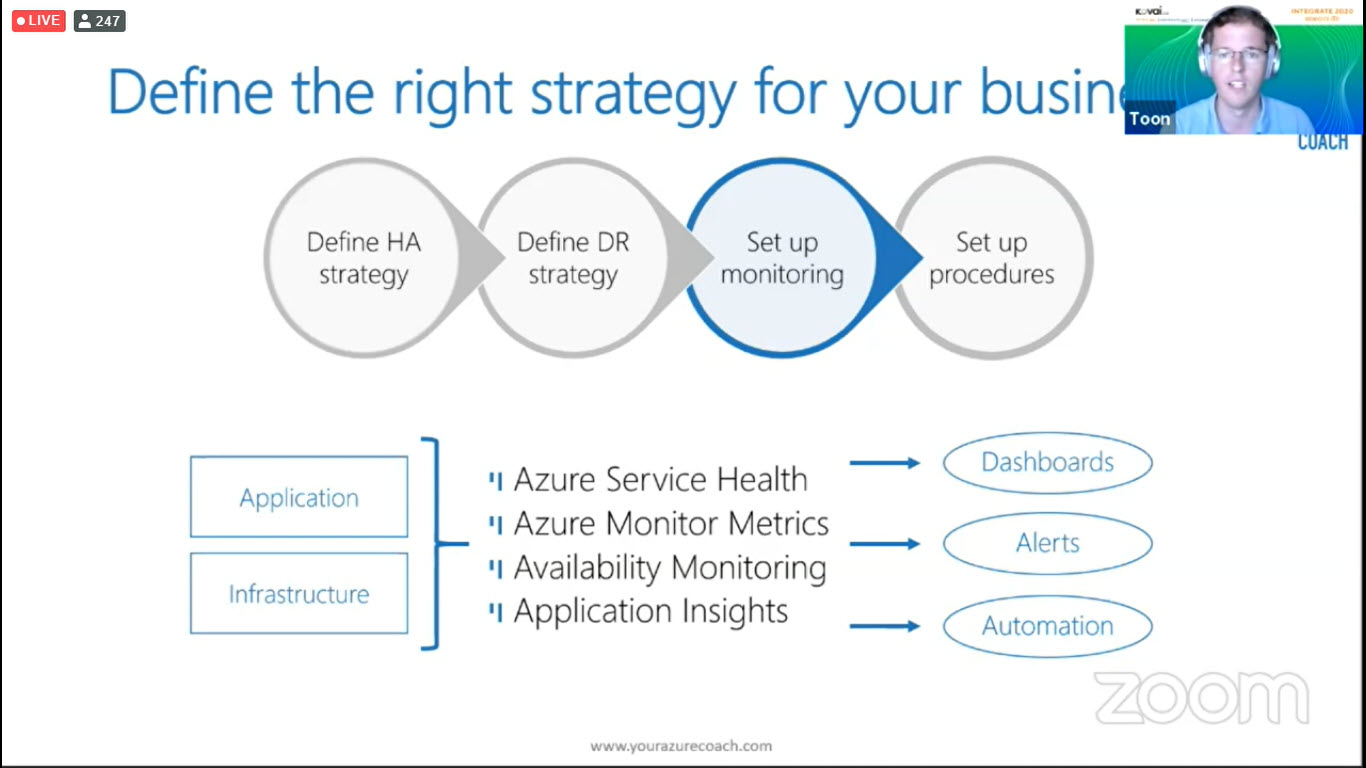
Set up Monitoring
You need to be aware/get alerted that there is an issue before it is going to affect your business/environment. There are multiple services available to monitor your application and infrastructure. Choose the right medium to be alerted like dashboard, alerts, automation.
Example: One of the best monitoring solutions for the Azure Integration services is nothing more than Turbo360. It offers various capabilities like Availability monitoring along with Auto-correct to ensure the business continuity, Business activity monitoring to perform end to end tracking on your Azure Serverless application and many more
Set up Procedures
Be aware that this is a team effort, the team needs to be knowledgeable about the architecture, disaster recovery, etc.,
Let us see the team’s key feature that should be aware of,
- Roles & responsibilities
- Privileged access rights
- Confidence through testing
- Team knowledge
- Team availability
- Automation is key
You must key the availability on the one hand and Cost complexity on the other hand.
Azure Integration Services
Now let us try to apply this in the Azure integration services and see about the challenges in the integration services and how to overcome them. We are going to cover,
- Logic Apps High Availability/ Disaster Recovery
- API Management High Availability/ Disaster Recovery
- Service Bus Disaster Recovery
- Event Grid Disaster Recovery
Logic Apps High Availability/ Disaster Recovery
Azure Logic Apps helps you orchestrate and integrate different services by providing hundreds of ready-to-use connectors, ranging from SQL Server or SAP to Azure Cognitive Services. The Logic Apps service is “serverless”, so you do not have to worry about scale or instances. All you must do is define the workflow with a trigger and the actions that the workflow performs.
Challenges
- There is no backup & restore option available.
- Running Logic Apps cannot be restored.
- There is no option to restore the connector state.
- EDI controls numbers and AS2 MIC values are stateful.
- Logic Apps request URL’s are randomly generated.
Solutions
- Use CI/CD pipelines to restore the Logic Apps definitions.
- Split business processes into short-running integrations.
- Avoid stateful triggers and/or remove input messages.
- Leverage the B2B disaster recovery capabilities.
- Store URLs during CI/CD Pipeline, implement regional if/else logic
API Management High Availability/ Disaster Recovery
The Azure API management offering helps to expose internal assets in the form of APIs to the outside world. A company can then create policies around the APIs, set rules, etc. It supports Disaster Recovery scenarios. There are a lot of aspects of the API service offering, like security, products, and developer portal.
Multi-region – Active/Active (HA)
- Only in Premium Tier
- Only covers the Gateway components
- Secondary becomes read-only during the failover
- Regional gateways are also directly accessible
Backup/Restore Active/Passive (DR)
- Restore in the max time of 30 min
- Restore Within the same tier
- References to an old region (Apps Insights)
- Backup expires after 30 days
- DIY with API/PoSh
- Not available in Consumption Tier
CI/CD HA/DR
- Requires 100% configure as code Users
- Requires 100% configure as code Groups
- Requires 100% configure as code Subscription keys
- Blue green deploy strategy possible
Service Bus Disaster Recovery
Microsoft Azure Service Bus is a fully managed enterprise integration message broker. Service Bus can decouple applications and services. Service Bus offers a reliable and secure platform for asynchronous transfer of data and state.
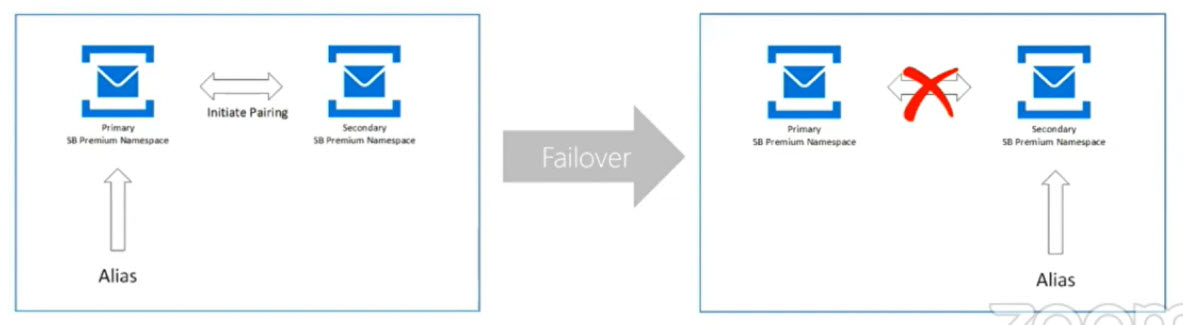
DR only available in Premium tier
- This includes an alias that redirects to the active namespace
- This only covers the metadata – not the messages itself
- Customer must trigger the failover
Event Grid Disaster Recovery
Event Grid’s automatic failover has different RPO’s and RTO’s for your metadata (event subscriptions, etc.) and data (events). If you need different specifications from below, you can still always implement your own client-side failover using the topic health APIs.
Out of the box server-side DR to the paired region for metadata
- Recovery point Objective
- Metadata: 0 minutes
- Data: 5 minutes
- Recovery Time Objective
- Metadata greater time than 60 minutes
- Data greater time than 60 minutes
You are responsible for client-side DR
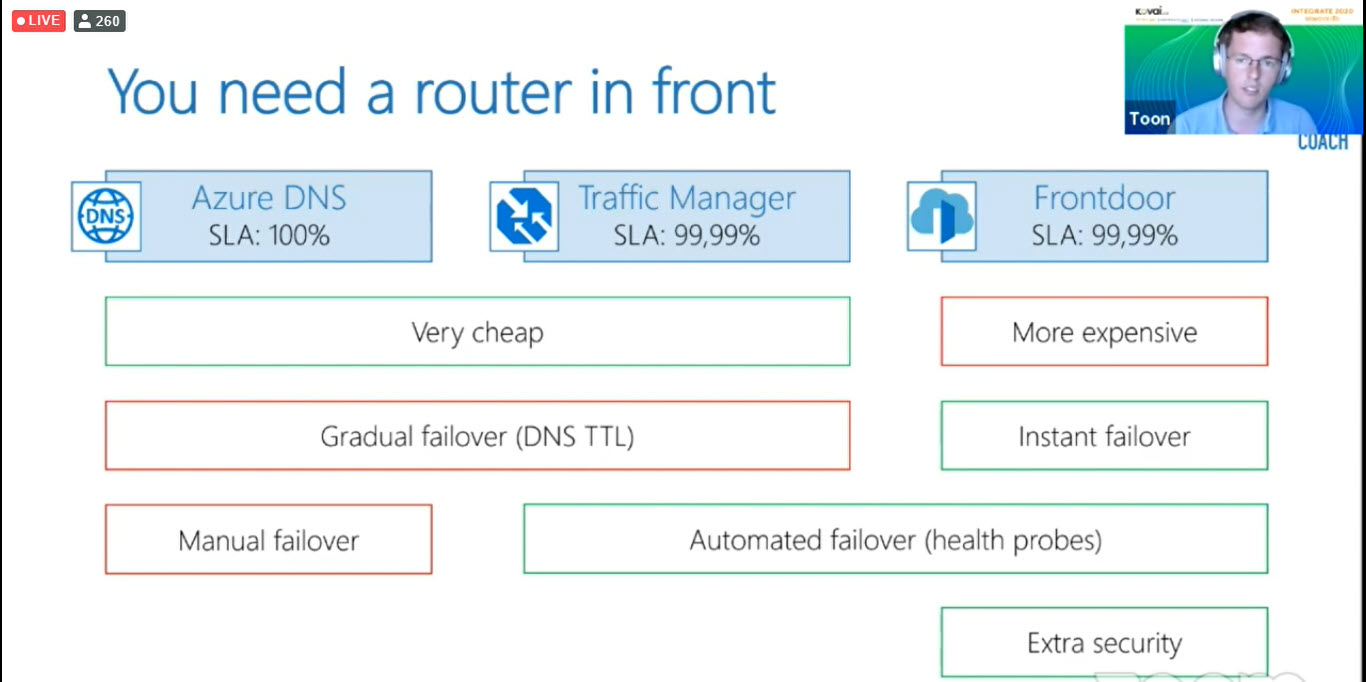
- Publishing events: failover from primary to secondary topic
- Subscribing events: router in front of the event handler
Case Study
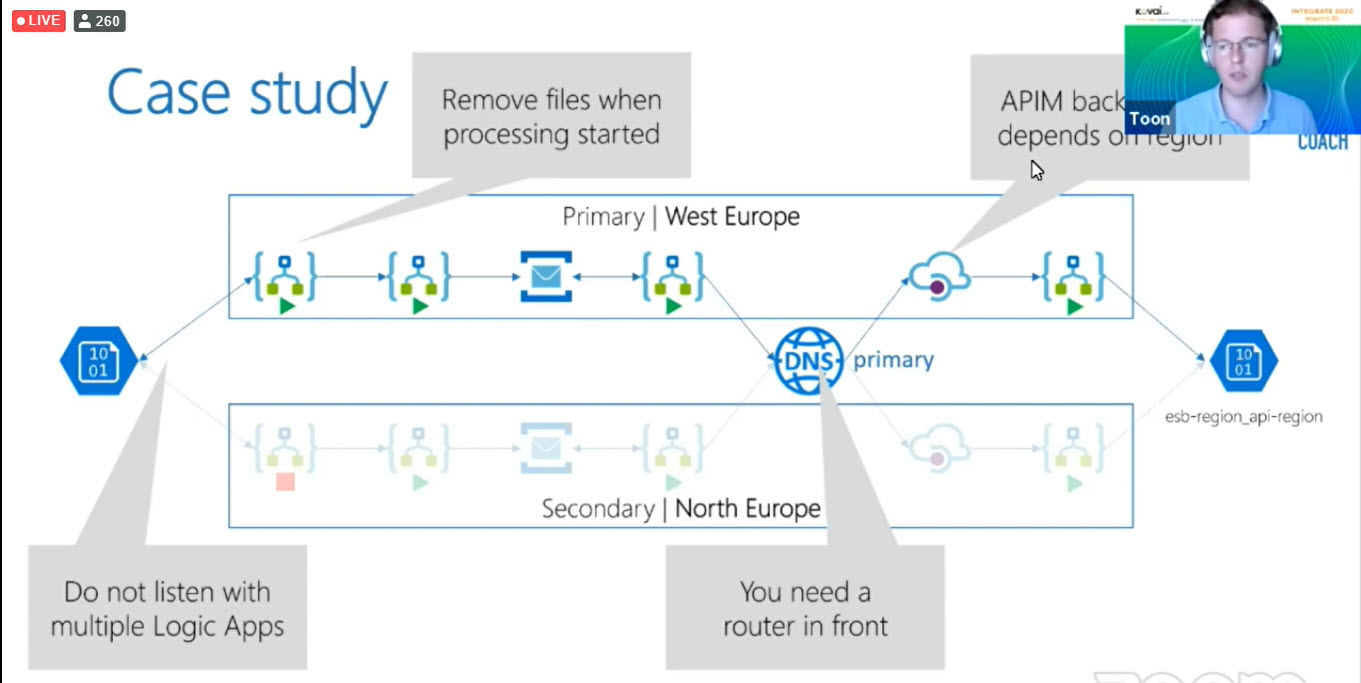
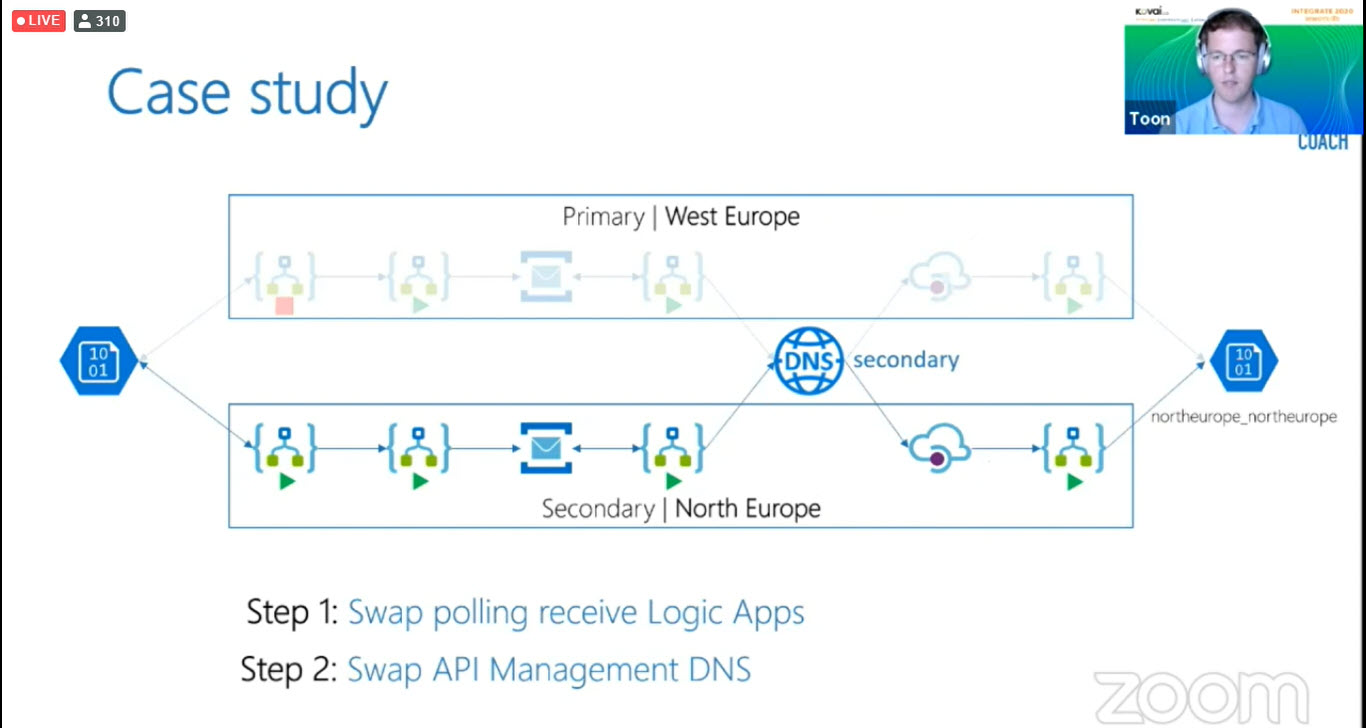
We had a customer with the following requirements.

Here is the example flow, this is an order invoice let’s see in detail. The EDI orders will arrive on the left-hand side which is a storage account. Have used two logic apps account it’s responsible for EDI parsing and translates into chronicle order. Then the order will be exposed to the Service Bus topic. The next logic app will involve order API and it’s behind the API management and the last logic apps are used to put the order into the storage account.
In the case study, we are going to swap the polling receive logics apps from West-Europe to North-Europe and followed by swap the API Management DNS.

Here is the comment to change the polling from West-Europe to North-Europe

So, if you have look at the Azure Storage Accounts, it has been changed the polling from West-Europe to North-Europe.
Key Learning
- It is all about risk mitigation, no 100% bullet-proof solutions
- Still global dependencies like Azure Active Directory and Azure DNS
- Do not use Logic Apps to monitor Logic Apps
- Use them in a paired region
- Foresee monitoring of the monitoring
- Be aware when eternal system applies IP restrictions
- Both active and passive IP ranges should be allowed
- Failover script should be independent of Azure (DevOps)
- Ensure you can run/modify it from localhost
- Do not rely on Azure Service Health
Conclusion
Think about the High availability and make the right way of your business. You must key the availability on the one hand and Cost complexity on the other hand.

