
About Azure Data Factory
In big data, relational, non-relational, and other storage technologies are frequently used to store raw, disorganized data. Yet, raw data alone lacks the context or meaning to offer analysts, data scientists, or business decision-makers actionable insights.
To transform these massive stores of raw data into usable business insights, big data requires a service that can orchestrate and operationalize processes. Azure Data Factory is a managed cloud solution for these challenging hybrid extract-transform-load (ETL), extract-load-transform (ELT), and data integration projects.
The cloud-based ETL and data integration service allows you to create data-driven workflows for orchestrating data movement and transforming data at scale. Using Azure Data Factory, you can create and schedule data-driven workflows (called pipelines) to ingest data from disparate data stores. You can build complex ETL processes that transform data visually with data flows or use compute services such as Azure HDInsight Hadoop, Azure Databricks, and Azure SQL Database.
What is Azure Data Factory Pipeline
A pipeline is a logical collection of activities that work together to complete a task. A pipeline, for example, could include activities that ingest and clean log data before launching a mapping data flow to analyze the log data. The pipeline enables users to manage the activities as a group rather than individually.
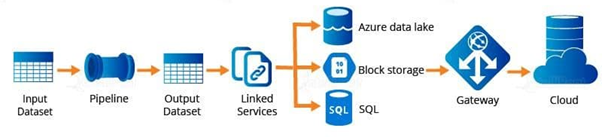
The activities in a pipeline define actions to perform on your data. For example, the user may use a copy activity to copy data from SQL Server to Azure Blob Storage. Then, use a data flow activity or a Databricks Notebook activity to process and transform data from the blob storage to an Azure Synapse Analytics pool, on top of which business intelligence reporting solutions are built.
Azure Data Factory Pipeline Monitoring using Turbo360
Pipeline monitoring is essential in the Azure Data factory scenario since the entire activity or business process gets affected if a pipeline run fails.
Though there is a monitoring option to check for failed runs in the Azure portal, Turbo360 comes with out-of-the-box capabilities for monitoring Azure Data Factory and its pipelines so that the users are notified, and corrective actions are also taken proactively.
Pipelines are recurring, and if the errors are not fixed, job failure also inherits this recurring nature. Knowing which job fails can save you money leading you towards pay for value from current pay for use.
The user should know what happens in the background when an Azure Data Factory pipeline fails or takes longer than expected. It is crucial to examine the average run time over some time and then set a threshold appropriately to recognize when the pipeline has taken longer than usual. With the monitoring options available in Turbo360, this can be achieved.
Consider a scenario where the data from an advanced Analytics tool is required to generate reports for important business process. Pipelines can address this requirement. If the pipelines fail, the data will not be available, and the whole process will be stopped. In this case, with Turbo360, the following can be performed:
- Monitor the pipeline and trigger alerts based on the count of failed activity runs
- Rerun the failed runs with the help of the automated tasks
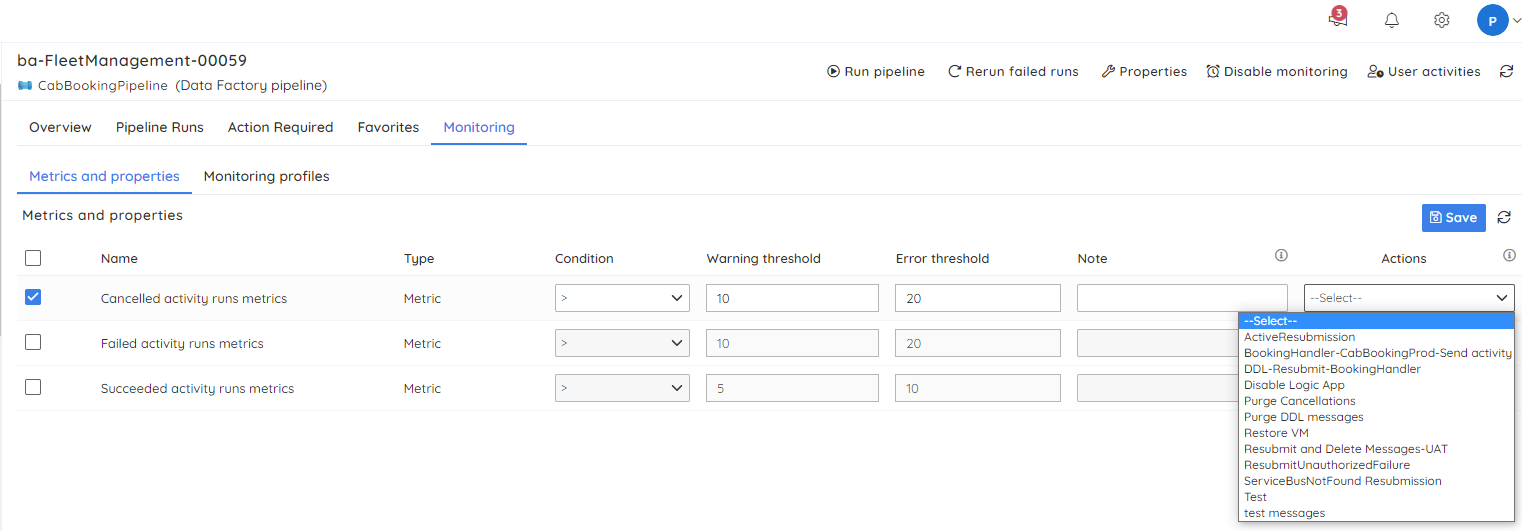
The alerts can be triggered to various notification channels like Teams, PageDuty, and OpsGenie, apart from sending emails. While configuring the monitoring settings for the pipelines, the user can select the specified action so that no manual intervention is required for corrective actions. This rerun option will help the business process continue and generate reports in the above-case scenario.
Pipeline failure management using Turbo360
With Turbo360, you can monitor the pipelines and manage failures in them effectively. The user can trigger a pipeline and also stop a pipeline execution. Turbo360 can retrieve the failed runs based on run status in a specific DateTime range. To find the cause of the failure, the user can view all the run activities and their execution status.
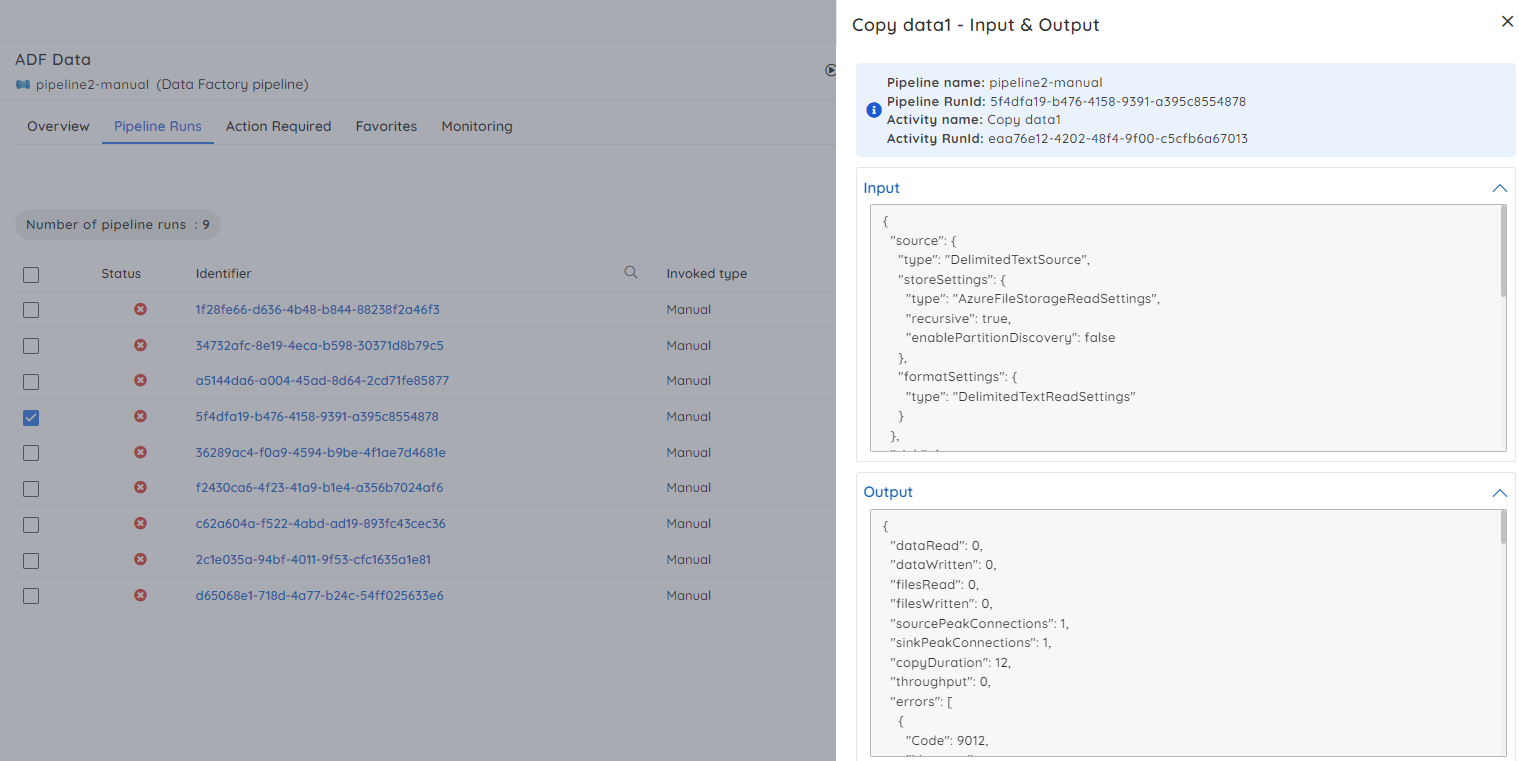
Once the cause is identified, Turbo360 provides an additional capability to investigate the input and output bindings and rerun the pipeline by dynamically passing the correct values to the already configured pipeline parameters without switching to the Azure portal.
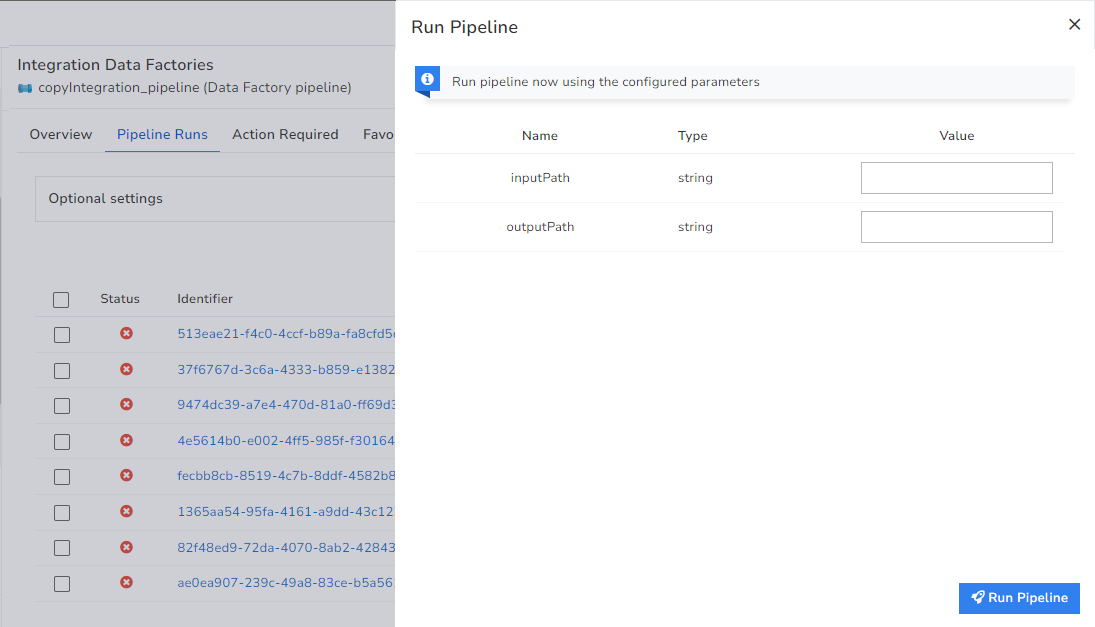
With Turbo360; Enterprises can efficiently analyze the failures in the Data Factory Pipelines and rectify the same with the least effort.
Apart from the capabilities mentioned above, Integration runtime associated with the Pipelines can also be monitored with Turbo360. The action required tab in the Pipelines pinpoints the exactly failed runs and what action is required for them. The filter option enables the user to filter the data based on the status of the trigger runs like Waiting and Cancelled.
The Integration Runtimes can also be viewed based on the filter conditions like access denied and stopped. The customizable performance dashboard help build dashboards to correlate failed activity runs and succeeded activity runs. It also helps the user to discover failed trends in the pipeline runs.
With Turbo360’s fine-grained access control mechanism, users can be given personalized access privileges on the features to avoid unauthorized access. All the activities performed by the users are audited and captured.
Conclusion
With Turbo360, every Azure resource can be managed and monitored effectively. The users can also get an overview of the relationship between these resources, which is unavailable in the Azure portal.
Now the Turbo360 capability is also extended to BizTalk Server integration, covering the hybrid scenario, which will be helpful for most of the users in the Integration space. Why not give Turbo360 a try and explore its vast capabilities? Happy monitoring 😊!

