
Azure SQL Database is at the heart of many applications running on Azure. Whether a company is migrating its on-premises applications to Azure or designing a new application from scratch, there are high chances of Azure SQL Database being considered and used.
A serverless offering?!
One may ask why Microsoft would provide a serverless offering for its PaaS database service?
The Serverless offering can be beneficial for situations where the load on your database is unpredictable or under heavy variations over time.
There is no autoscaling functionality built-in Azure SQL Database allowing us to define rules for scaling up or down our database instance. Still, the Serverless offering is designed to address that purpose.
Why would I care?
We typically use many cloud services to host our applications (e.g., Azure App Service, Virtual Machine Scale Sets, Azure Functions) to allow autoscaling to meet the growing demand. Hence, the database can become the bottleneck in our solution. The Serverless offering of Azure SQL Database helps address this situation.
How is that different from the Elastic Pool offering?
The Elastic Pool offering addresses a different need. It is intended to define a pool of resources (CPU, RAM, I/O) shared by a set of databases. It is assumed that the needs of all databases don’t exceed the allowed resources pool.
For that to work:
- Either the resources required by all the databases are less or equal to the capacity of the pool (assuming all databases are in use at the same time)
- Or not all databases are in use simultaneously, although the sum of the resources they need might be greater than the pool’s capacity.
Serverless offering intends to scale (up or down) the resources of a given database to meet the demand. Thus, as demand increases, the number of vCores allocated to the database. The same happens when the demand decreases.
How do I create a serverless instance of SQL Database?
We’ll see how to do this from the Azure portal but keep in mind that you can, of course, do it using CLI tools for automation purposes.
You start by creating a SQL Database instance, just as usual. You then click “Configure database” to select the offering:
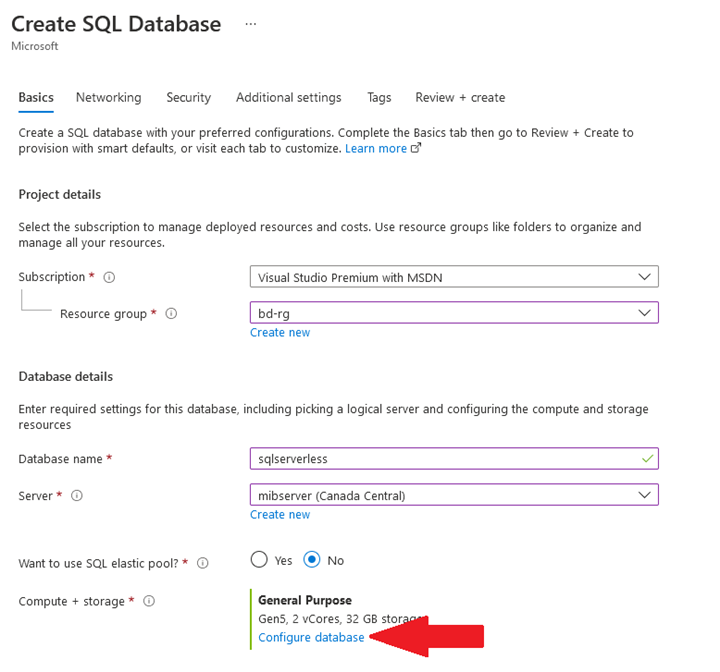
Select the “General Purpose” service tier and pick “Serverless” as the compute tier. You’ll then be able to select the hardware configuration, min and max number of vCores, the max size of the database and enable/disable/configure the auto-pause delay:
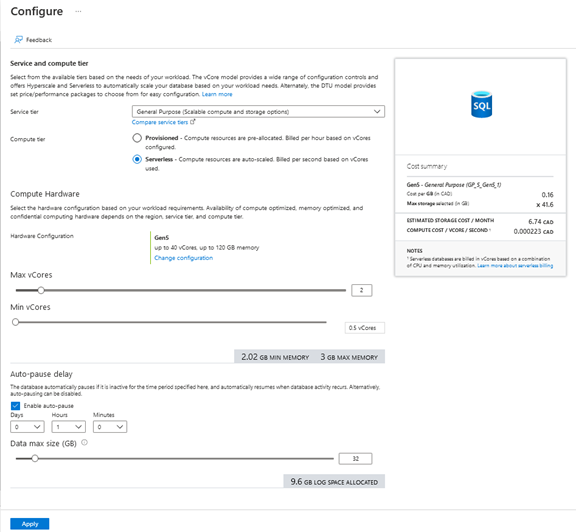
The rest of the configuration is the same as any other SQL Database instance creation.
One word about the hardware configuration: you might want to choose an appropriate hardware configuration depending on the purpose of your database. As you see below, you can pick from configurations that are compute-optimized, memory-optimized and so on:
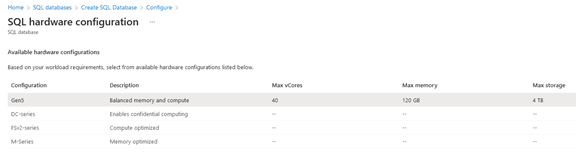
Note that not all hardware configurations are available in every region.
What triggers scaling?
Scaling is triggered based on resource utilization, and they do independently from one another. This helps to align better the number of resources provided and costs with workload demand. So, for example, we might see a significant increase in memory allocation in the case of a given query reading lots of data but not an increase in CPU allocation as it’s not needed.
How is the cost calculated?
Storage and compute are calculated separately, and to keep costs under control; you can set limits for both the CPU (number of vCores) and the memory.
As an example, look at this estimated cost formula:

We see that the storage cost is fixed (whether we use all the storage capacity we defined in the configuration) but the compute cost varies depending on how many vCores we use per second.
Also, keep in mind that the auto-pause feature can help keep costs low since when the database is in a “pause” state, compute fees do not incur, only storage fees.
To evaluate the costs, you can use the Azure Pricing Calculator. Here’s an example:
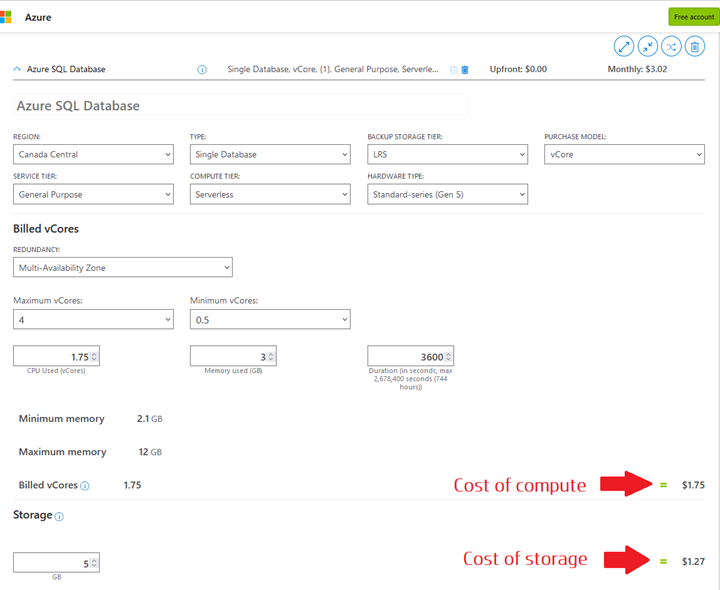
The estimated cost here is the minimum cost you’ll be charged, based on the minimum amount of CPU and RAM you entered. It is important to note that as scaling happens, so is the number of vCores and the amount of RAM, hence the cost.
Is there any latency to be expected during scaling?
Scaling in the serverless offering happens quickly (usually in under a second), making it very practical and attractive. There should thus not be a perceptible latency.
However, suppose you’ve configured the “auto-pause” functionality, and your database has gone into sleep mode. In that case, you may expect latency on your requests until the database has been fully wakening up.
Should I use auto-pause?
The purpose of the “auto-pause” functionality is to save you costs. When the database hasn’t been in use for a duration that you set, it goes into a sleep, which means its compute resources are deallocated. Hence, compute charges aren’t incurred anymore; only storage costs are. However, when your database resumes, it may take a relatively long time to reach it again. During that time, requests to your database are likely to fail. Your application has then to be resilient.
On the other hand, if you don’t use auto-pause, compute resources will be charged even if your database isn’t in use, which may cost a lot.
So, in general, if you know (or expect) that your database won’t be in use most of the time, it is a good idea to configure auto-pause.
There are, however, scenarios where you can’t use auto-pause:
- Long-term backup retention
- Utilize Data Sync
- Geo-Replication
When is auto-pause triggered?
Auto-pausing is triggered if all of the following conditions are true for the duration of the auto-pause delay:
- Number of sessions = 0
- CPU = 0 for user workload running in the user resource pool
Can I configure an existing database to use the serverless offering?
Yes. You can change the SKU of your database instance at any point in time. Hence, you can set your database to use the serverless offering even if the database already exists.
From the portal, go to “Compute + storage” (under “Settings”) and change the SKU:
You can obviously also do that via CLI.
Is there any impact on the application code?
The database is now configured to scale in response to demand variation. However, during the scaling process, the database will be temporarily unreachable. Although this downtime is very short (usually under a second), your application might generate errors when communicating with the database during the scaling phase.
Your application should be resilient by performing retries. If your application is built in .NET, you can leverage libraries such as Polly to help you infuse resiliency into your code.
Apart from that, there’s no other impact on your application. The connection string remains the same and the way your code works with the database.
To sum it up…
Azure SQL Database is an excellent database service, and with its various offerings, it can certainly suit your need. In a nutshell:
- DTU-based SKUs are used when we need a balanced ratio between CPU, RAM, and I/O performance.
- vCore-based SKUs are to be used when we need better control over the CPU, RAM and I/O performance allocated to the database instance.
- Serverless is used when there are heavy variations on the load over time.

